
If you are looking for the full AZ-104 study guide: https://www.cloud13.ch/2023/10/31/az-104-study-guide-microsoft-azure-administrator/
It is clear to me that networking is probably the most complex topic in Azure. The concept is very different from the on-premises world, you have so many options and a lot of topics to understand. Let us focus on Azure storage as the next topic. As always, I will follow John Savill’s guidance and look for the documentation online.
Storage Accounts
An Azure storage account contains all of your Azure Storage data objects: blobs, files, queues, and tables. The storage account provides a unique namespace for your Azure Storage data that’s accessible from anywhere in the world over HTTP or HTTPS. Data in your storage account is durable and highly available, secure, and massively scalable.
When naming your storage account, keep these rules in mind:
- Storage account names must be between 3 and 24 characters in length and may contain numbers and lowercase letters only.
- Your storage account name must be unique within Azure. No two storage accounts can have the same name.
Azure Storage Redundancy
Data in an Azure Storage account is always replicated three times in the primary region. Azure Storage offers two options for how your data is replicated in the primary region:
- Locally redundant storage (LRS) copies your data synchronously three times within a single physical location in the primary region. LRS is the least expensive replication option, but isn’t recommended for applications requiring high availability or durability.

- Zone-redundant storage (ZRS) copies your data synchronously across three Azure availability zones in the primary region. For applications requiring high availability, Microsoft recommends using ZRS in the primary region, and also replicating to a secondary region.
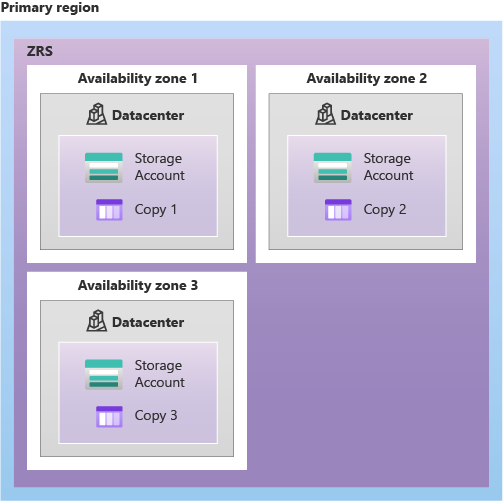
Redundancy in a secondary region
For applications requiring high durability, you can choose to additionally copy the data in your storage account to a secondary region that is hundreds of miles away from the primary region. If your storage account is copied to a secondary region, then your data is durable even in the case of a complete regional outage or a disaster in which the primary region isn’t recoverable.
Azure Storage offers two options for copying your data to a secondary region:
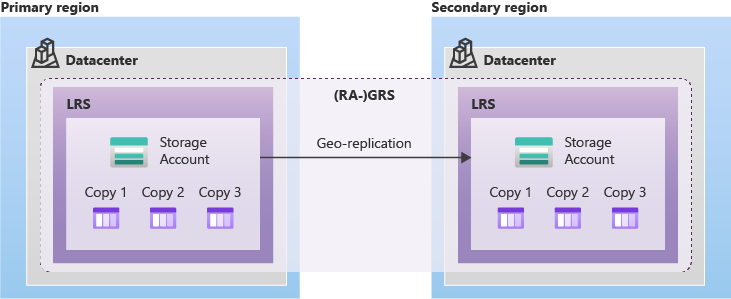
- Geo-redundant storage (GRS) copies your data synchronously three times within a single physical location in the primary region using LRS. It then copies your data asynchronously to a single physical location in the secondary region. Within the secondary region, your data is copied synchronously three times using LRS.
- Geo-zone-redundant storage (GZRS) copies your data synchronously across three Azure availability zones in the primary region using ZRS. It then copies your data asynchronously to a single physical location in the secondary region. Within the secondary region, your data is copied synchronously three times using LRS.
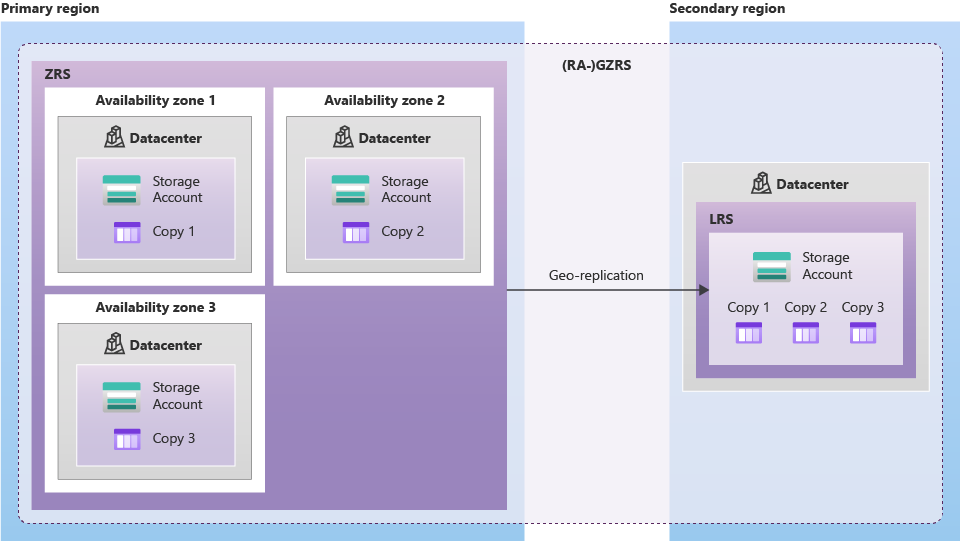
Geo-redundant storage (with GRS or GZRS) replicates your data to another physical location in the secondary region to protect against regional outages. With an account configured for GRS or GZRS, data in the secondary region is not directly accessible to users or applications, unless a failover occurs. The failover process updates the DNS entry provided by Azure Storage so that the secondary endpoint becomes the new primary endpoint for your storage account. During the failover process, your data is inaccessible. After the failover is complete, you can read and write data to the new primary region.
The following table describes key parameters for each redundancy option:
| Parameter | LRS | ZRS | GRS/RA-GRS | GZRS/RA-GZRS |
|---|---|---|---|---|
| Percent durability of objects over a given year | at least 99.999999999% (11 9’s) | at least 99.9999999999% (12 9’s) | at least 99.99999999999999% (16 9’s) | at least 99.99999999999999% (16 9’s) |
| Availability for read requests | At least 99.9% (99% for cool or archive access tiers) | At least 99.9% (99% for cool access tier) |
At least 99.9% (99% for cool or archive access tiers) for GRS At least 99.99% (99.9% for cool or archive access tiers) for RA-GRS |
At least 99.9% (99% for cool access tier) for GZRS At least 99.99% (99.9% for cool access tier) for RA-GZRS |
| Availability for write requests | At least 99.9% (99% for cool or archive access tiers) | At least 99.9% (99% for cool access tier) | At least 99.9% (99% for cool or archive access tiers) | At least 99.9% (99% for cool access tier) |
| Number of copies of data maintained on separate nodes | Three copies within a single region | Three copies across separate availability zones within a single region | Six copies total, including three in the primary region and three in the secondary region | Six copies total, including three across separate availability zones in the primary region and three locally redundant copies in the secondary region |
Azure Blobs
Azure Storage offers three types of blob storage:
- Block Blobs. Block blobs are composed of blocks and are ideal for storing text or binary files, and for uploading large files efficiently.
- Append Blobs. Append blobs are also made up of blocks, but they are optimized for append operations, making them ideal for logging scenarios.
- Page blobs. Page blobs are made up of 512-byte pages up to 8 TB in total size and are designed for frequent random read/write operations. Page blobs are the foundation of Azure IaaS Disks.
Overview of Azure page blobs
Page blobs are a collection of 512-byte pages, which provide the ability to read/write arbitrary ranges of bytes. Hence, page blobs are ideal for storing index-based and sparse data structures like OS and data disks for Virtual Machines and Databases. For example, Azure SQL DB uses page blobs as the underlying persistent storage for its databases. Moreover, page blobs are also often used for files with Range-Based updates.
Key features of Azure page blobs are its REST interface, the durability of the underlying storage, and the seamless migration capabilities to Azure. These features are discussed in more detail in the next section. In addition, Azure page blobs are currently supported on two types of storage: Premium Storage and Standard Storage. Premium Storage is designed specifically for workloads requiring consistent high performance and low latency making premium page blobs ideal for high performance storage scenarios. Standard storage accounts are more cost effective for running latency-insensitive workloads.
Azure page blobs are the backbone of the virtual disks platform for Azure IaaS. Both Azure OS and data disks are implemented as virtual disks where data is durably persisted in the Azure Storage platform and then delivered to the virtual machines for maximum performance. Azure Disks are persisted in Hyper-V VHD format and stored as a page blob in Azure Storage. In addition to using virtual disks for Azure IaaS VMs, page blobs also enable PaaS and DBaaS scenarios such as Azure SQL DB service, which currently uses page blobs for storing SQL data, enabling fast random read-write operations for the database. Another example would be if you have a PaaS service for shared media access for collaborative video editing applications, page blobs enable fast access to random locations in the media. It also enables fast and efficient editing and merging of the same media by multiple users.
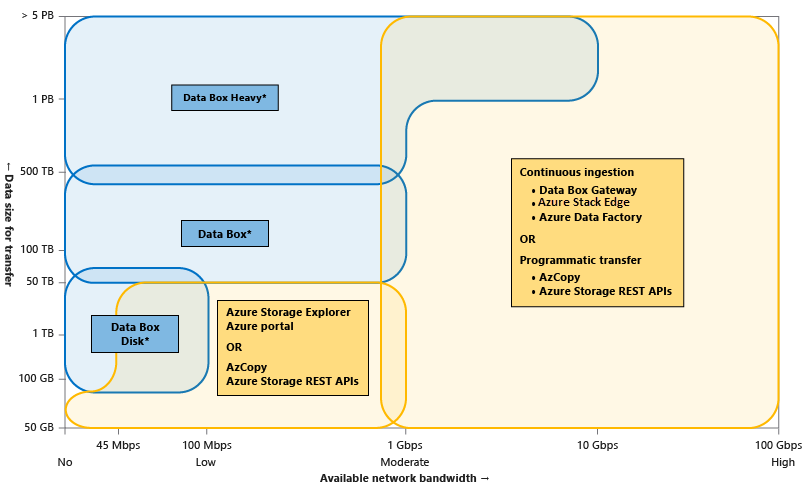
The following visual illustrates the guidelines to choose the various Azure data transfer tools depending upon the network bandwidth available for transfer, data size intended for transfer, and frequency of the transfer.
Premium block blob storage accounts
Premium block blob storage accounts make data available via high-performance hardware. Data is stored on solid-state drives (SSDs) which are optimized for low latency. SSDs provide higher throughput compared to traditional hard drives. File transfer is much faster because data is stored on instantly accessible memory chips. All parts of a drive accessible at once. By contrast, the performance of a hard disk drive (HDD) depends on the proximity of data to the read/write heads.
Access tiers for blob data
Data stored in the cloud grows at an exponential pace. To manage costs for your expanding storage needs, it can be helpful to organize your data based on how frequently it will be accessed and how long it will be retained. Azure storage offers different access tiers so that you can store your blob data in the most cost-effective manner based on how it’s being used. Azure Storage access tiers include:
- Hot tier – An online tier optimized for storing data that is accessed or modified frequently. The hot tier has the highest storage costs, but the lowest access costs.
- Cool tier – An online tier optimized for storing data that is infrequently accessed or modified. Data in the cool tier should be stored for a minimum of 30 days. The cool tier has lower storage costs and higher access costs compared to the hot tier.
- Cold tier – An online tier optimized for storing data that is rarely accessed or modified, but still requires fast retrieval. Data in the cold tier should be stored for a minimum of 90 days. The cold tier has lower storage costs and higher access costs compared to the cool tier.
- Archive tier – An offline tier optimized for storing data that is rarely accessed, and that has flexible latency requirements, on the order of hours. Data in the archive tier should be stored for a minimum of 180 days.
Object replication for block blobs
Object replication asynchronously copies block blobs between a source storage account and a destination account. Some scenarios supported by object replication include:
- Minimizing latency. Object replication can reduce latency for read requests by enabling clients to consume data from a region that is in closer physical proximity.
- Increase efficiency for compute workloads. With object replication, compute workloads can process the same sets of block blobs in different regions.
- Optimizing data distribution. You can process or analyze data in a single location and then replicate just the results to additional regions.
- Optimizing costs. After your data has been replicated, you can reduce costs by moving it to the archive tier using life cycle management policies.

Append Blobs
An append blob is composed of blocks and is optimized for append operations. When you modify an append blob, blocks are added to the end of the blob only, via the Append Block operation. Updating or deleting of existing blocks is not supported. Unlike a block blob, an append blob does not expose its block IDs.
Each block in an append blob can be a different size, up to a maximum of 4 MiB, and an append blob can include up to 50,000 blocks. The maximum size of an append blob is therefore slightly more than 195 GiB (4 MiB X 50,000 blocks).
Azure Files
Azure Files offers fully managed file shares in the cloud that are accessible via the industry standard Server Message Block (SMB) protocol, Network File System (NFS) protocol, and Azure Files REST API. Azure file shares can be mounted concurrently by cloud or on-premises deployments.
SMB Azure file shares are accessible from Windows, Linux, and macOS clients. NFS Azure file shares are accessible from Linux clients. Additionally, SMB Azure file shares can be cached on Windows servers with Azure File Sync for fast access near where the data is being used.
Active Directory as Authentication Source
On-premises Active Directory Domain Services (AD DS) integration with Azure Files provides the methods for storing directory data while making it available to network users and administrators. Security is integrated with AD DS through logon authentication and access control to objects in the directory. With a single network logon, administrators can manage directory data and organization throughout their network, and authorized network users can access resources anywhere on the network. AD DS is commonly adopted by enterprises in on-premises environments or on cloud-hosted VMs, and AD DS credentials are used for access control.
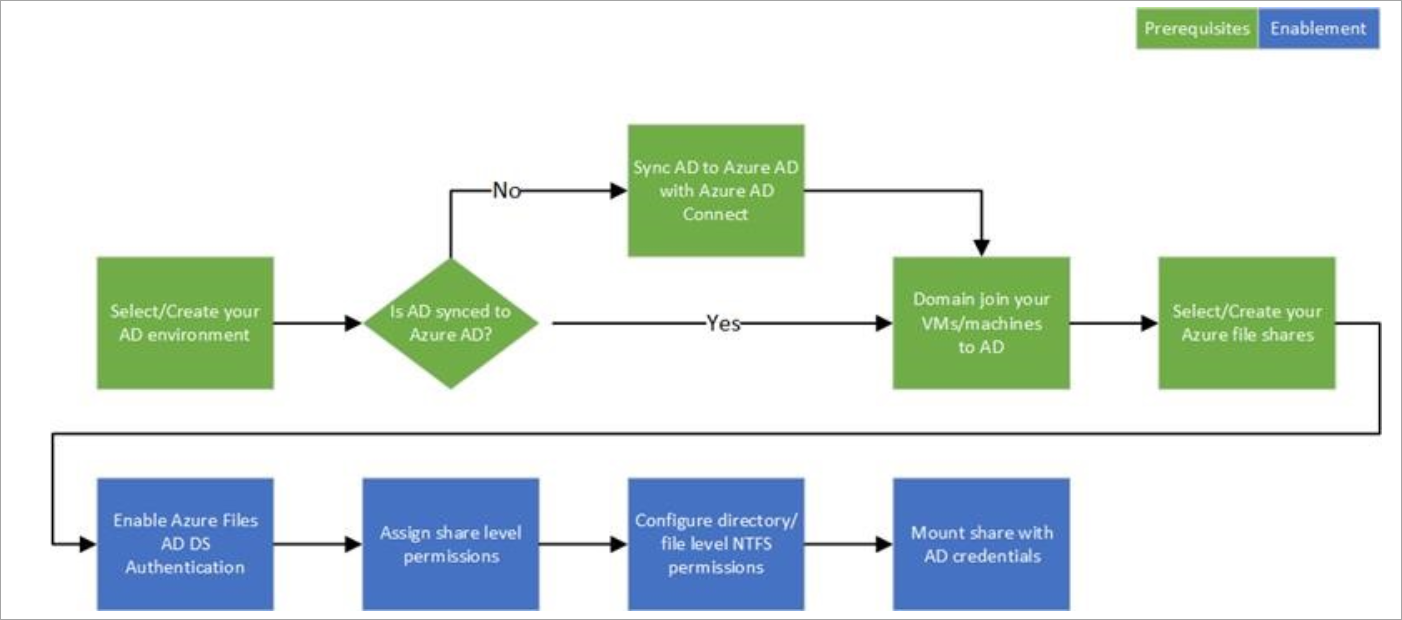
Azure File Sync
Azure File Sync enables centralizing your organization’s file shares in Azure Files, while keeping the flexibility, performance, and compatibility of a Windows file server. While some users may opt to keep a full copy of their data locally, Azure File Sync additionally can transform Windows Server into a quick cache of your Azure file share. You can use any protocol that’s available on Windows Server to access your data locally, including SMB, NFS, and FTPS. You can have as many caches as you need across the world.

Azure Queue Storage
Azure Queue Storage is a service for storing large numbers of messages. You access messages from anywhere in the world via authenticated calls using HTTP or HTTPS. A queue message can be up to 64 KB in size. A queue may contain millions of messages, up to the total capacity limit of a storage account.
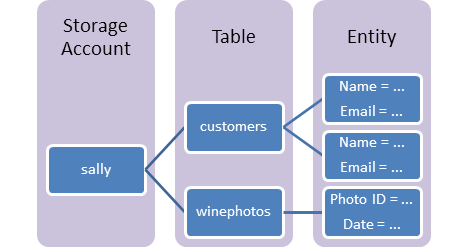
Azure Table Storage
Azure Table storage stores large amounts of structured data. The service is a NoSQL datastore which accepts authenticated calls from inside and outside the Azure cloud. Azure tables are ideal for storing structured, non-relational data. Common uses of Table storage include:
- Storing TBs of structured data capable of serving web scale applications
- Storing datasets that don’t require complex joins, foreign keys, or stored procedures and can be denormalized for fast access
- Quickly querying data using a clustered index
- Accessing data using the OData protocol and LINQ queries with WCF Data Service .NET Libraries
You can use Table storage to store and query huge sets of structured, non-relational data, and your tables will scale as demand increases.
Azure Managed Disks
Azure managed disks are block-level storage volumes that are managed by Azure and used with Azure Virtual Machines. Managed disks are like a physical disk in an on-premises server but, virtualized. With managed disks, all you have to do is specify the disk size, the disk type, and provision the disk. Once you provision the disk, Azure handles the rest.
The available types of disks are ultra disks, premium solid-state drives (SSD), standard SSDs, and standard hard disk drives (HDD). For information about each individual disk type, see Select a disk type for IaaS VMs.
Disk type comparison
The following table provides a comparison of the five disk types to help you decide which to use.
| Ultra disk | Premium SSD v2 | Premium SSD | Standard SSD | ||
|---|---|---|---|---|---|
| Disk type | SSD | SSD | SSD | SSD | HDD |
| Scenario | IO-intensive workloads such as SAP HANA, top tier databases (for example, SQL, Oracle), and other transaction-heavy workloads. | Production and performance-sensitive workloads that consistently require low latency and high IOPS and throughput | Production and performance sensitive workloads | Web servers, lightly used enterprise applications and dev/test | Backup, non-critical, infrequent access |
| Max disk size | 65,536 GiB | 65,536 GiB | 32,767 GiB | 32,767 GiB | 32,767 GiB |
| Max throughput | 4,000 MB/s | 1,200 MB/s | 900 MB/s | 750 MB/s | 500 MB/s |
| Max IOPS | 160,000 | 80,000 | 20,000 | 6,000 | 2,000, 3,000* |
| Usable as OS Disk? | No | No | Yes | Yes | Yes |
* Only applies to disks with performance plus (preview) enabled.
Note: You can adjust ultra disk IOPS and throughput performance at runtime without detaching the disk from the virtual machine. After a performance resize operation has been issued on a disk, it can take up to an hour for the change to take effect. Up to four performance resize operations are permitted during a 24-hour window.




























