Are you preparing for the Oracle Cloud Infrastructure (OCI) 2025 Architect Associate Exam? Me too. 🙂
Whether you are just starting your cloud journey or leveling up your OCI skills, the 2025 Architect Associate exam is designed to test your understanding of core OCI services across compute, networking, storage, IAM, and more. It is about knowing how to build and manage scalable, secure, high-performing infrastructure on Oracle Cloud Infrastructure.
In this guide, I have broken down everything you need to know and mapped it directly to Oracle’s official documentation.
The following table lists the exam objectives and their weightings.
Last year, when I was studying for the 2024 version of the exam without any prior knowledge of OCI, I only used the online course and the official documentation to pass the exam.
It is clear to me that networking is probably the most complex topic in Azure. The concept is very different from the on-premises world, you have so many options and a lot of topics to understand. Let us focus on Azure storage as the next topic. As always, I will follow John Savill’s guidance and look for the documentation online.
Storage Accounts
An Azure storage account contains all of your Azure Storage data objects: blobs, files, queues, and tables. The storage account provides a unique namespace for your Azure Storage data that’s accessible from anywhere in the world over HTTP or HTTPS. Data in your storage account is durable and highly available, secure, and massively scalable.
When naming your storage account, keep these rules in mind:
Storage account names must be between 3 and 24 characters in length and may contain numbers and lowercase letters only.
Your storage account name must be unique within Azure. No two storage accounts can have the same name.
Azure Storage Redundancy
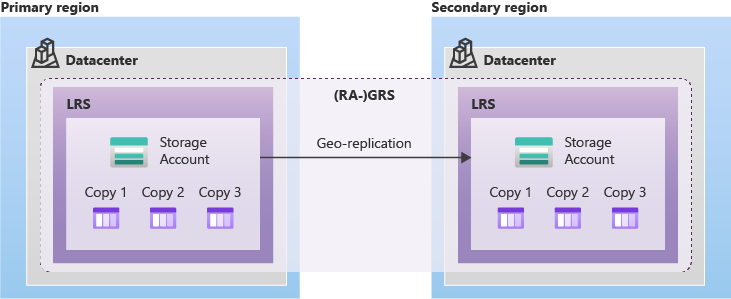
Data in an Azure Storage account is always replicated three times in the primary region. Azure Storage offers two options for how your data is replicated in the primary region:
Locally redundant storage (LRS)copies your data synchronously three times within a single physical location in the primary region. LRS is the least expensive replication option, but isn’t recommended for applications requiring high availability or durability.
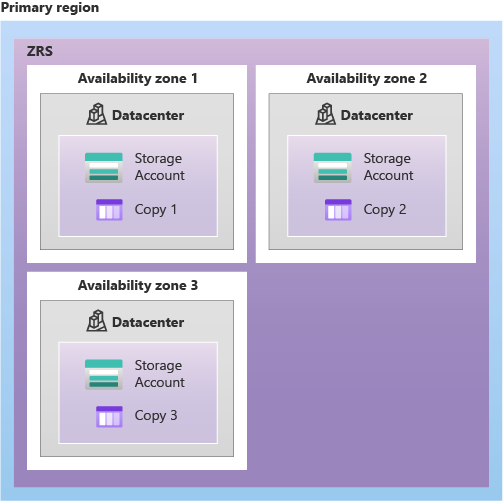
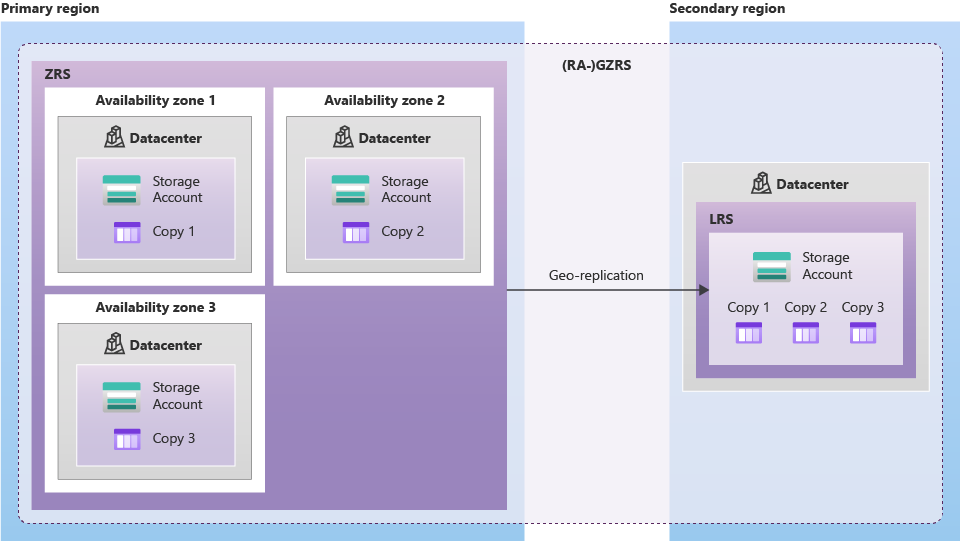
Zone-redundant storage (ZRS)copies your data synchronously across three Azure availability zones in the primary region. For applications requiring high availability, Microsoft recommends using ZRS in the primary region, and also replicating to a secondary region.
Redundancy in a secondary region
For applications requiring high durability, you can choose to additionally copy the data in your storage account to a secondary region that is hundreds of miles away from the primary region. If your storage account is copied to a secondary region, then your data is durable even in the case of a complete regional outage or a disaster in which the primary region isn’t recoverable.
Azure Storage offers two options for copying your data to a secondary region:
Geo-redundant storage (GRS)copies your data synchronously three times within a single physical location in the primary region using LRS. It then copies your data asynchronously to a single physical location in the secondary region. Within the secondary region, your data is copied synchronously three times using LRS.
Geo-zone-redundant storage (GZRS)copies your data synchronously across three Azure availability zones in the primary region using ZRS. It then copies your data asynchronously to a single physical location in the secondary region. Within the secondary region, your data is copied synchronously three times using LRS.
Geo-redundant storage (with GRS or GZRS) replicates your data to another physical location in the secondary region to protect against regional outages. With an account configured for GRS or GZRS, data in the secondary region is not directly accessible to users or applications, unless a failover occurs. The failover process updates the DNS entry provided by Azure Storage so that the secondary endpoint becomes the new primary endpoint for your storage account. During the failover process, your data is inaccessible. After the failover is complete, you can read and write data to the new primary region.
The following table describes key parameters for each redundancy option:
Parameter
LRS
ZRS
GRS/RA-GRS
GZRS/RA-GZRS
Percent durability of objects over a given year
at least 99.999999999% (11 9’s)
at least 99.9999999999% (12 9’s)
at least 99.99999999999999% (16 9’s)
at least 99.99999999999999% (16 9’s)
Availability for read requests
At least 99.9% (99% for cool or archive access tiers)
At least 99.9% (99% for cool access tier)
At least 99.9% (99% for cool or archive access tiers) for GRS
At least 99.99% (99.9% for cool or archive access tiers) for RA-GRS
At least 99.9% (99% for cool access tier) for GZRS
At least 99.99% (99.9% for cool access tier) for RA-GZRS
Availability for write requests
At least 99.9% (99% for cool or archive access tiers)
At least 99.9% (99% for cool access tier)
At least 99.9% (99% for cool or archive access tiers)
At least 99.9% (99% for cool access tier)
Number of copies of data maintained on separate nodes
Three copies within a single region
Three copies across separate availability zones within a single region
Six copies total, including three in the primary region and three in the secondary region
Six copies total, including three across separate availability zones in the primary region and three locally redundant copies in the secondary region
Azure Blobs
Azure Storage offers three types of blob storage:
Block Blobs. Block blobs are composed of blocks and are ideal for storing text or binary files, and for uploading large files efficiently.
Append Blobs. Append blobs are also made up of blocks, but they are optimized for append operations, making them ideal for logging scenarios.
Page blobs. Page blobs are made up of 512-byte pages up to 8 TB in total size and are designed for frequent random read/write operations. Page blobs are the foundation of Azure IaaS Disks.
Overview of Azure page blobs
Page blobs are a collection of 512-byte pages, which provide the ability to read/write arbitrary ranges of bytes. Hence, page blobs are ideal for storing index-based and sparse data structures like OS and data disks for Virtual Machines and Databases. For example, Azure SQL DB uses page blobs as the underlying persistent storage for its databases. Moreover, page blobs are also often used for files with Range-Based updates.
Key features of Azure page blobs are its REST interface, the durability of the underlying storage, and the seamless migration capabilities to Azure. These features are discussed in more detail in the next section. In addition, Azure page blobs are currently supported on two types of storage: Premium Storage and Standard Storage. Premium Storage is designed specifically for workloads requiring consistent high performance and low latency making premium page blobs ideal for high performance storage scenarios. Standard storage accounts are more cost effective for running latency-insensitive workloads.
Azure page blobs are the backbone of the virtual disks platform for Azure IaaS. Both Azure OS and data disks are implemented as virtual disks where data is durably persisted in the Azure Storage platform and then delivered to the virtual machines for maximum performance. Azure Disks are persisted in Hyper-V VHD format and stored as a page blob in Azure Storage. In addition to using virtual disks for Azure IaaS VMs, page blobs also enable PaaS and DBaaS scenarios such as Azure SQL DB service, which currently uses page blobs for storing SQL data, enabling fast random read-write operations for the database. Another example would be if you have a PaaS service for shared media access for collaborative video editing applications, page blobs enable fast access to random locations in the media. It also enables fast and efficient editing and merging of the same media by multiple users.
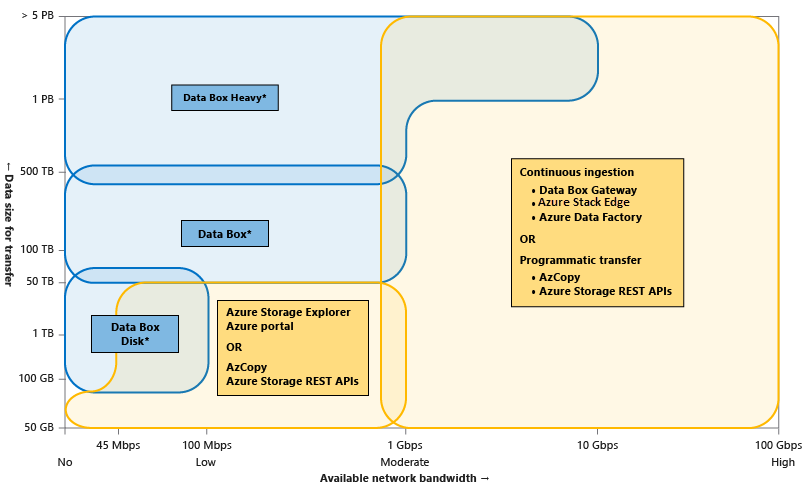
The following visual illustrates the guidelines to choose the various Azure data transfer tools depending upon the network bandwidth available for transfer, data size intended for transfer, and frequency of the transfer.
Premium block blob storage accounts
Premium block blob storage accounts make data available via high-performance hardware. Data is stored on solid-state drives (SSDs) which are optimized for low latency. SSDs provide higher throughput compared to traditional hard drives. File transfer is much faster because data is stored on instantly accessible memory chips. All parts of a drive accessible at once. By contrast, the performance of a hard disk drive (HDD) depends on the proximity of data to the read/write heads.
Access tiers for blob data
Data stored in the cloud grows at an exponential pace. To manage costs for your expanding storage needs, it can be helpful to organize your data based on how frequently it will be accessed and how long it will be retained. Azure storage offers different access tiers so that you can store your blob data in the most cost-effective manner based on how it’s being used. Azure Storage access tiers include:
Hot tier– An online tier optimized for storing data that is accessed or modified frequently. The hot tier has the highest storage costs, but the lowest access costs.
Cool tier– An online tier optimized for storing data that is infrequently accessed or modified. Data in the cool tier should be stored for a minimum of30days. The cool tier has lower storage costs and higher access costs compared to the hot tier.
Cold tier– An online tier optimized for storing data that is rarely accessed or modified, but still requires fast retrieval. Data in the cold tier should be stored for a minimum of90days. The cold tier has lower storage costs and higher access costs compared to the cool tier.
Archive tier– An offline tier optimized for storing data that is rarely accessed, and that has flexible latency requirements, on the order of hours. Data in the archive tier should be stored for a minimum of 180 days.
Object replication for block blobs
Object replication asynchronously copies block blobs between a source storage account and a destination account. Some scenarios supported by object replication include:
Minimizing latency.Object replication can reduce latency for read requests by enabling clients to consume data from a region that is in closer physical proximity.
Increase efficiency for compute workloads.With object replication, compute workloads can process the same sets of block blobs in different regions.
Optimizing data distribution.You can process or analyze data in a single location and then replicate just the results to additional regions.
Optimizing costs.After your data has been replicated, you can reduce costs by moving it to the archive tier using life cycle management policies.
Append Blobs
An append blob is composed of blocks and is optimized for append operations. When you modify an append blob, blocks are added to the end of the blob only, via the Append Block operation. Updating or deleting of existing blocks is not supported. Unlike a block blob, an append blob does not expose its block IDs.
Each block in an append blob can be a different size, up to a maximum of 4 MiB, and an append blob can include up to 50,000 blocks. The maximum size of an append blob is therefore slightly more than 195 GiB (4 MiB X 50,000 blocks).
Azure Files
Azure Files offers fully managed file shares in the cloud that are accessible via the industry standard Server Message Block (SMB) protocol, Network File System (NFS) protocol, and Azure Files REST API. Azure file shares can be mounted concurrently by cloud or on-premises deployments.
SMB Azure file shares are accessible from Windows, Linux, and macOS clients. NFS Azure file shares are accessible from Linux clients. Additionally, SMB Azure file shares can be cached on Windows servers with Azure File Sync for fast access near where the data is being used.
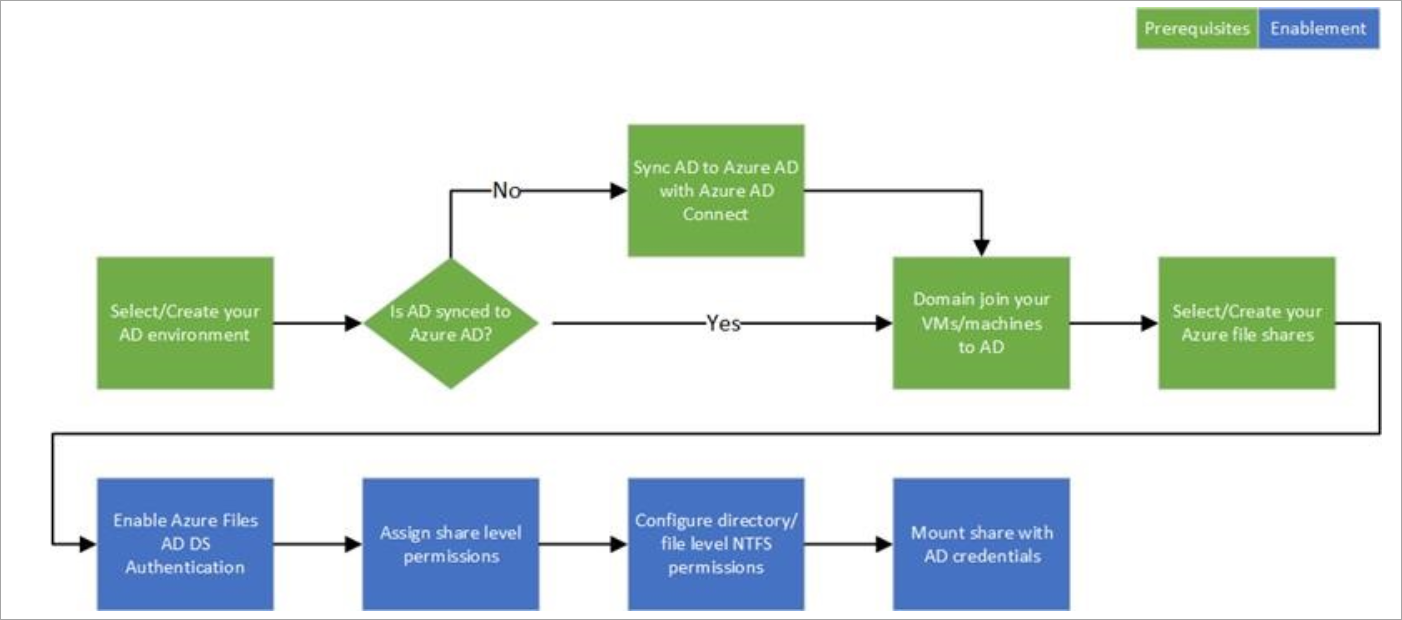
Active Directory as Authentication Source
On-premises Active Directory Domain Services (AD DS) integration with Azure Files provides the methods for storing directory data while making it available to network users and administrators. Security is integrated with AD DS through logon authentication and access control to objects in the directory. With a single network logon, administrators can manage directory data and organization throughout their network, and authorized network users can access resources anywhere on the network. AD DS is commonly adopted by enterprises in on-premises environments or on cloud-hosted VMs, and AD DS credentials are used for access control.
Azure File Sync
Azure File Sync enables centralizing your organization’s file shares in Azure Files, while keeping the flexibility, performance, and compatibility of a Windows file server. While some users may opt to keep a full copy of their data locally, Azure File Sync additionally can transform Windows Server into a quick cache of your Azure file share. You can use any protocol that’s available on Windows Server to access your data locally, including SMB, NFS, and FTPS. You can have as many caches as you need across the world.
Azure Queue Storage
Azure Queue Storage is a service for storing large numbers of messages. You access messages from anywhere in the world via authenticated calls using HTTP or HTTPS. A queue message can be up to 64 KB in size. A queue may contain millions of messages, up to the total capacity limit of a storage account.
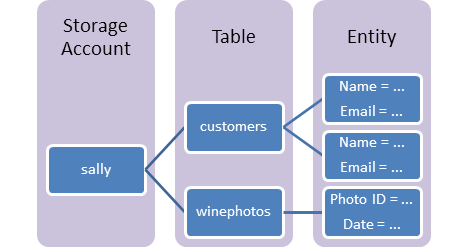
Azure Table Storage
Azure Table storage stores large amounts of structured data. The service is a NoSQL datastore which accepts authenticated calls from inside and outside the Azure cloud. Azure tables are ideal for storing structured, non-relational data. Common uses of Table storage include:
Storing TBs of structured data capable of serving web scale applications
Storing datasets that don’t require complex joins, foreign keys, or stored procedures and can be denormalized for fast access
Quickly querying data using a clustered index
Accessing data using the OData protocol and LINQ queries with WCF Data Service .NET Libraries
You can use Table storage to store and query huge sets of structured, non-relational data, and your tables will scale as demand increases.
Azure Managed Disks
Azure managed disks are block-level storage volumes that are managed by Azure and used with Azure Virtual Machines. Managed disks are like a physical disk in an on-premises server but, virtualized. With managed disks, all you have to do is specify the disk size, the disk type, and provision the disk. Once you provision the disk, Azure handles the rest.
The available types of disks are ultra disks, premium solid-state drives (SSD), standard SSDs, and standard hard disk drives (HDD). For information about each individual disk type, seeSelect a disk type for IaaS VMs.
Disk type comparison
The following table provides a comparison of the five disk types to help you decide which to use.
Ultra disk
Premium SSD v2
Premium SSD
Standard SSD
Standard HDD
Disk type
SSD
SSD
SSD
SSD
HDD
Scenario
IO-intensive workloads such asSAP HANA, top tier databases (for example, SQL, Oracle), and other transaction-heavy workloads.
Production and performance-sensitive workloads that consistently require low latency and high IOPS and throughput
Production and performance sensitive workloads
Web servers, lightly used enterprise applications and dev/test
Backup, non-critical, infrequent access
Max disk size
65,536 GiB
65,536 GiB
32,767 GiB
32,767 GiB
32,767 GiB
Max throughput
4,000 MB/s
1,200 MB/s
900 MB/s
750 MB/s
500 MB/s
Max IOPS
160,000
80,000
20,000
6,000
2,000, 3,000*
Usable as OS Disk?
No
No
Yes
Yes
Yes
* Only applies to disks with performance plus (preview) enabled.
Note: You can adjust ultra disk IOPS and throughput performance at runtime without detaching the disk from the virtual machine. After a performance resize operation has been issued on a disk, it can take up to an hour for the change to take effect. Up to four performance resize operations are permitted during a 24-hour window.
In part 1, I covered vNets, public IPs, vNet peering, NSGs and Azure Firewall. Part 2 is about DNS services, S2S VPN, Express Route, vWAN, Endpoints, Azure Load Balancers and Azure App Gateway.
Azure DNS Services
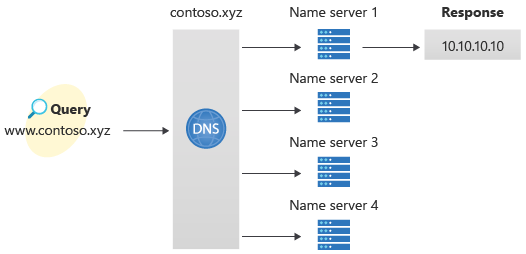
Azure DNS is a hosting service for DNS domains that provides name resolution by using Microsoft Azure infrastructure. By hosting your domains in Azure, you can manage your DNS records by using the same credentials, APIs, tools, and billing as your other Azure services.
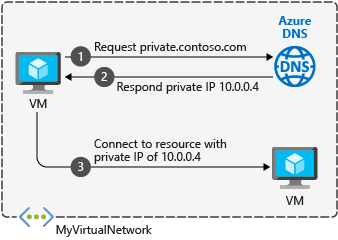
Azure Private DNS provides a reliable, secure DNS service to manage and resolve domain names in a virtual network without the need to add a custom DNS solution. By using private DNS zones, you can use your own custom domain names rather than the Azure-provided names available today.
The records contained in a private DNS zone aren’t resolvable from the Internet. DNS resolution against a private DNS zone works only from virtual networks that are linked to it.
When you create a private DNS zone, Azure stores the zone data as a global resource. This means that the private zone is not dependent on a single VNet or region. You can link the same private zone to multiple VNets in different regions. If service is interrupted in one VNet, your private zone is still available.
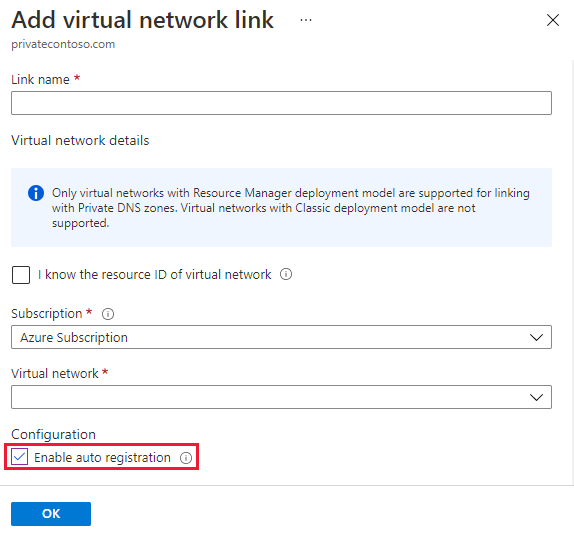
The Azure DNS private zones auto registration feature manages DNS records for virtual machines deployed in a virtual network. When you link a virtual network with a private DNS zone with this setting enabled, a DNS record gets created for each virtual machine deployed in the virtual network.
Note: Auto registration works only for virtual machines. For all other resources like internal load balancers, you can create DNS records manually in the private DNS zone linked to the virtual network.
You can also configure Azure DNS to resolve host names in your public domain. For example, if you purchased the contoso.xyz domain name from a domain name registrar, you can configure Azure DNS to host the contoso.xyz domain and resolve www.contoso.xyz to the IP address of your web server or web app.
First of all, to create a site-to-site (S2S) VPN, you need a VPN Gateway.
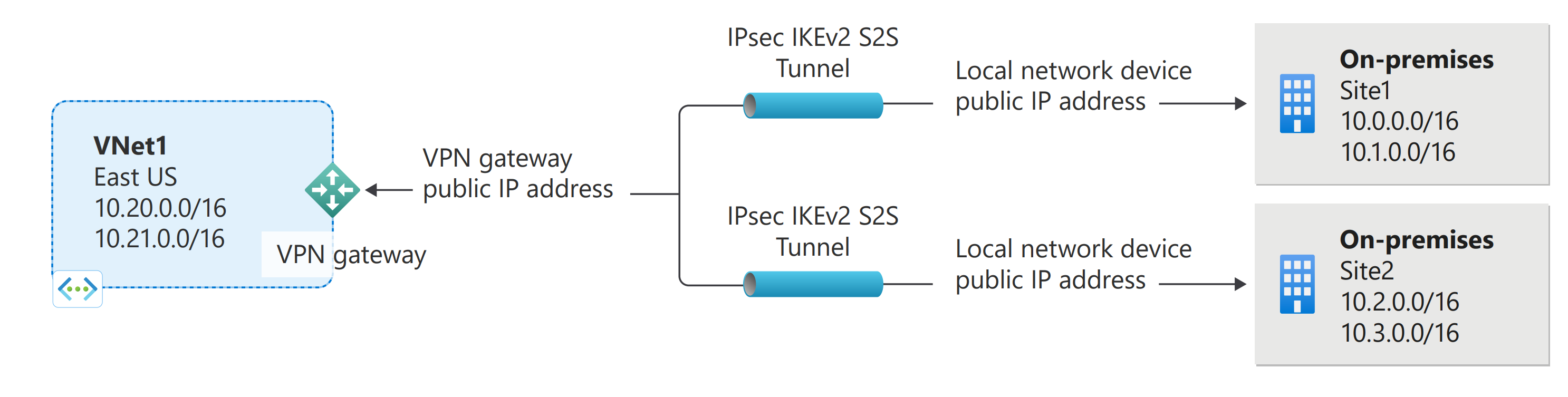
A VPN gateway is a type of virtual network gateway. A VPN gateway sends encrypted traffic between your virtual network and your on-premises location across a public connection. You can also use a VPN gateway to send traffic between virtual networks. When you create a VPN gateway, you use the -GatewayType value ‘Vpn’.
A Site-to-site (S2S) VPN gateway connection is a connection over IPsec/IKE (IKEv1 or IKEv2) VPN tunnel. S2S connections can be used for cross-premises and hybrid configurations. A S2S connection requires a VPN device located on-premises that has a public IP address assigned to it. For information about selecting a VPN device, see the VPN Gateway FAQ – VPN devices.
VPN Gateway can be configured in active-standby mode using one public IP or in active-active mode using two public IPs. In active-standby mode, one IPsec tunnel is active and the other tunnel is in standby. In this setup, traffic flows through the active tunnel, and if some issue happens with this tunnel, the traffic switches over to the standby tunnel. Setting up VPN Gateway in active-active mode isrecommendedin which both the IPsec tunnels are simultaneously active, with data flowing through both tunnels at the same time. An additional advantage of active-active mode is that customers experience higher throughputs.
You can create more than one VPN connection from your virtual network gateway, typically connecting to multiple on-premises sites. When working with multiple connections, you must use a RouteBased VPN type (known as a dynamic gateway when working with classic VNets). Because each virtual network can only have one VPN gateway, all connections through the gateway share the available bandwidth. This type of connection is sometimes referred to as a “multi-site” connection.
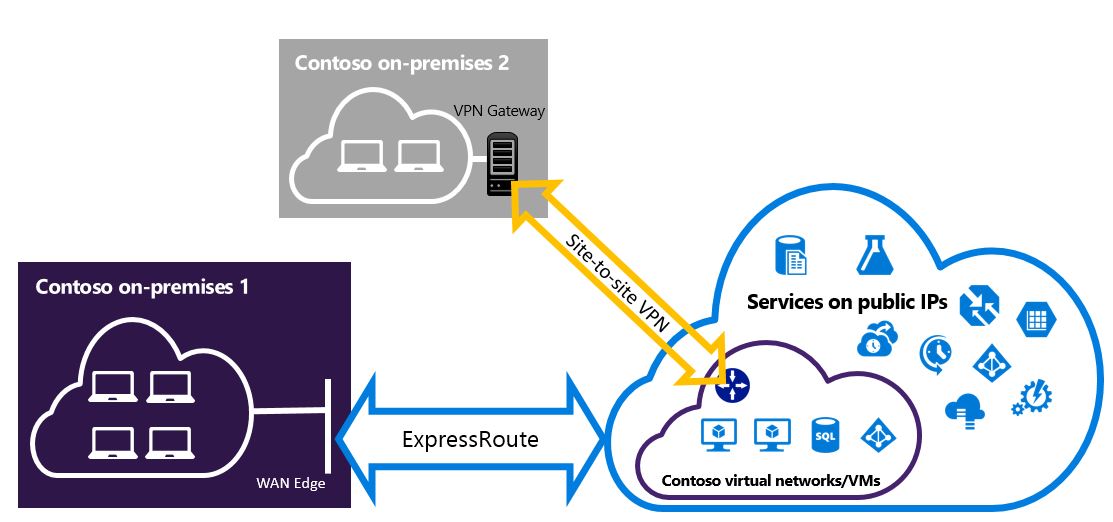
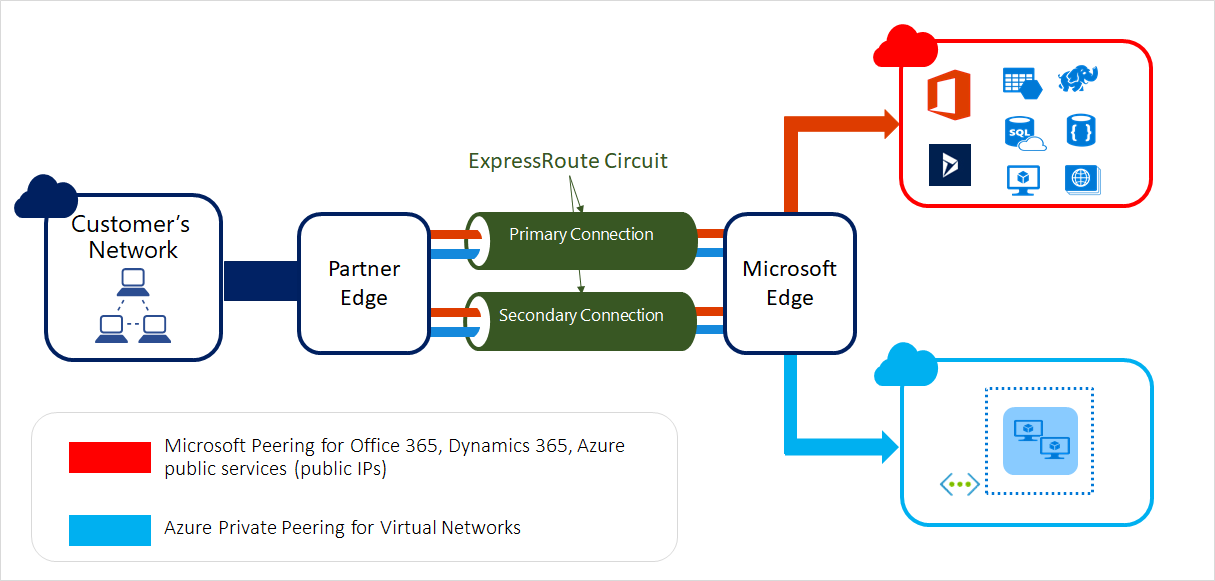
ExpressRoute lets you extend your on-premises networks into the Microsoft cloud over a private connection with the help of a connectivity provider. With ExpressRoute, you can establish connections to Microsoft cloud services, such as Microsoft Azure and Microsoft 365.
Connectivity can be from an any-to-any (IP VPN) network, a point-to-point Ethernet network, or a virtual cross-connection through a connectivity provider at a colocation facility. ExpressRoute connections don’t go over the public Internet. This allows ExpressRoute connections to offer more reliability, faster speeds, consistent latencies, and higher security than typical connections over the Internet. For information on how to connect your network to Microsoft using ExpressRoute, see ExpressRoute connectivity models.
Across on-premises connectivity with ExpressRoute Global Reach
You can enable ExpressRoute Global Reach to exchange data across your on-premises sites by connecting your ExpressRoute circuits. For example, if you have a private data center in California connected to an ExpressRoute circuit in Silicon Valley and another private data center in Texas connected to an ExpressRoute circuit in Dallas.
With ExpressRoute Global Reach, you can connect your private data centers together through these two ExpressRoute circuits. Your cross data-center traffic will traverse through the Microsoft network.
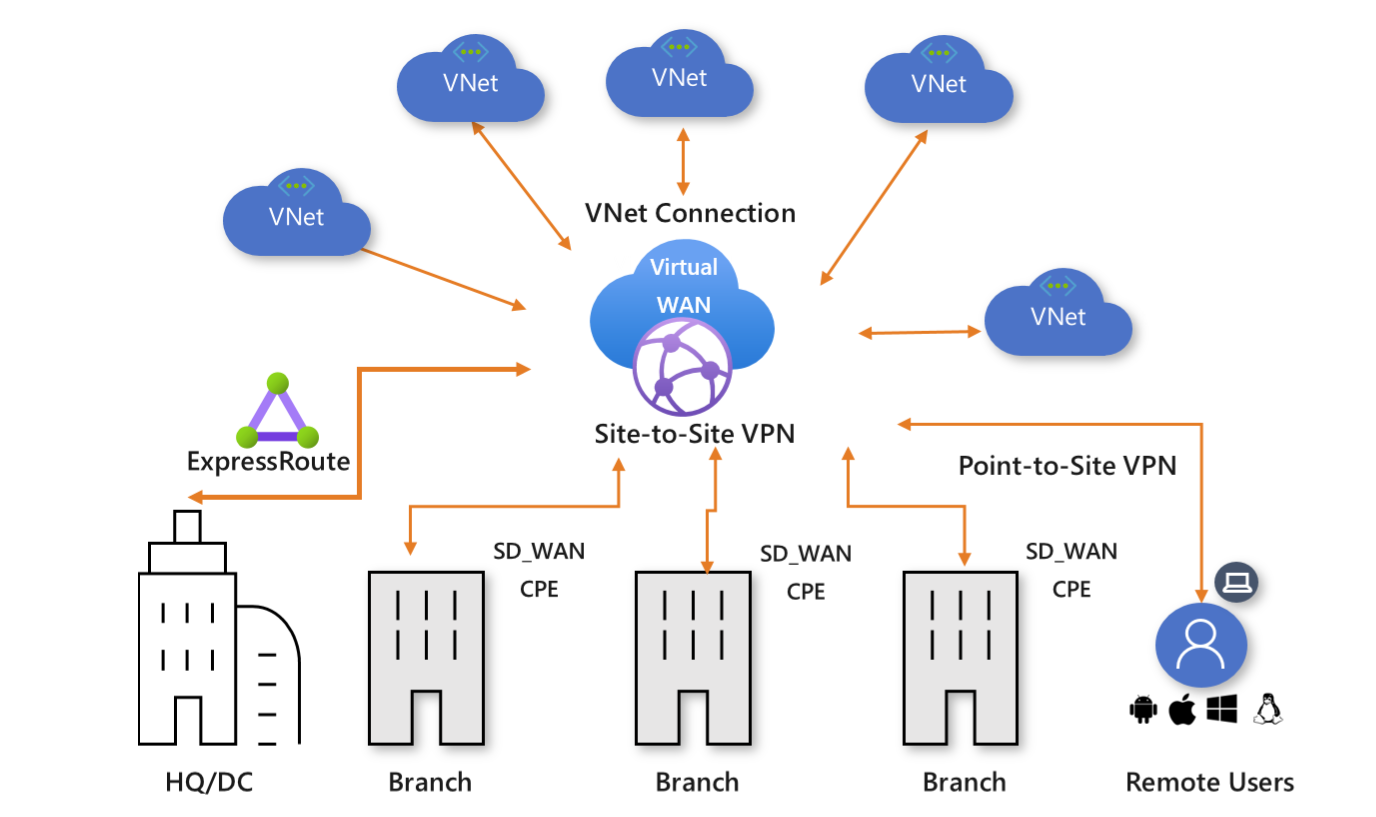
Azure Virtual WAN is a networking service that brings many networking, security, and routing functionalities together to provide a single operational interface. Some of the main features include:
Branch connectivity (via connectivity automation from Virtual WAN Partner devices such as SD-WAN or VPN CPE)
Site-to-site VPN connectivity
Remote user VPN connectivity (point-to-site)
Private connectivity (ExpressRoute)
Intra-cloud connectivity (transitive connectivity for virtual networks)
VPN ExpressRoute inter-connectivity
Routing, Azure Firewall, and encryption for private connectivity
The Virtual WAN architecture is a hub and spoke architecture with scale and performance built in for branches (VPN/SD-WAN devices), users (Azure VPN/OpenVPN/IKEv2 clients), ExpressRoute circuits, and virtual networks. It enables a global transit network architecture, where the cloud hosted network ‘hub’ enables transitive connectivity between endpoints that may be distributed across different types of ‘spokes’.
Improved security for your Azure service resources: VNet private address spaces can overlap. You can’t use overlapping spaces to uniquely identify traffic that originates from your VNet. Service endpoints enable securing of Azure service resources to your virtual network by extending VNet identity to the service. Once you enable service endpoints in your virtual network, you can add a virtual network rule to secure the Azure service resources to your virtual network. The rule addition provides improved security by fully removing public internet access to resources and allowing traffic only from your virtual network.
Optimal routing for Azure service traffic from your virtual network: Today, any routes in your virtual network that force internet traffic to your on-premises and/or virtual appliances also force Azure service traffic to take the same route as the internet traffic. Service endpoints provide optimal routing for Azure traffic.Endpoints always take service traffic directly from your virtual network to the service on the Microsoft Azure backbone network. Keeping traffic on the Azure backbone network allows you to continue auditing and monitoring outbound Internet traffic from your virtual networks, through forced-tunneling, without impacting service traffic. For more information about user-defined routes and forced-tunneling, seeAzure virtual network traffic routing.
Simple to set up with less management overhead: You no longer need reserved, public IP addresses in your virtual networks to secure Azure resources through IP firewall. There are no Network Address Translation (NAT) or gateway devices required to set up the service endpoints. You can configure service endpoints through a single selection on a subnet. There’s no extra overhead to maintaining the endpoints.
Private Endpoints
A private endpoint is a network interface that uses a private IP address from your virtual network. This network interface connects you privately and securely to a service that’s powered by Azure Private Link. By enabling a private endpoint, you’re bringing the service into your virtual network.
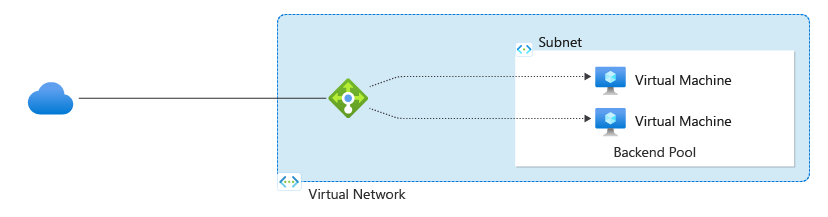
With Azure Load Balancer, you can scale your applications and create highly available services. Load balancer supports both inbound and outbound scenarios. Load balancer provides low latency and high throughput, and scales up to millions of flows for all TCP and UDP applications.
Key scenarios that you can accomplish using Azure Standard Load Balancer include:
Load balanceinternalandexternaltraffic to Azure virtual machines.
Increase availability by distributing resourceswithinandacrosszones.
Standard load balancer provides multi-dimensional metrics throughAzure Monitor. These metrics can be filtered, grouped, and broken out for a given dimension. They provide current and historic insights into performance and health of your service.Insights for Azure Load Balanceroffers a preconfigured dashboard with useful visualizations for these metrics. Resource Health is also supported. ReviewStandard load balancer diagnosticsfor more details.
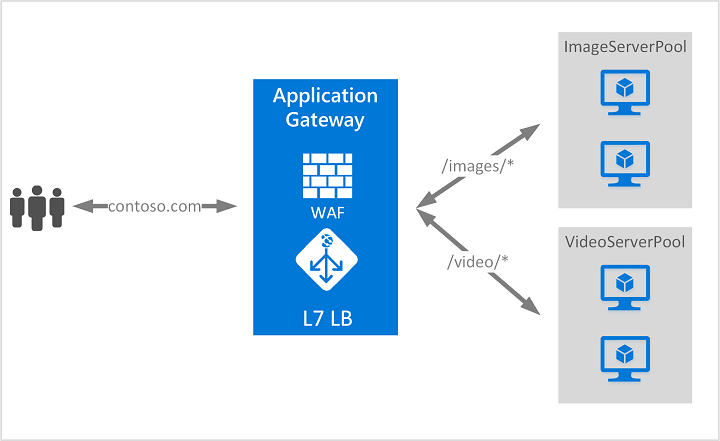
Azure Application Gateway is a web traffic (OSI layer 7) load balancer that enables you to manage traffic to your web applications. Traditional load balancers operate at the transport layer (OSI layer 4 – TCP and UDP) and route traffic based on source IP address and port, to a destination IP address and port.
Application Gateway can make routing decisions based on additional attributes of an HTTP request, for example URI path or host headers. For example, you can route traffic based on the incoming URL. So if/imagesis in the incoming URL, you can route traffic to a specific set of servers (known as a pool) configured for images. If/videois in the URL, that traffic is routed to another pool that’s optimized for videos.
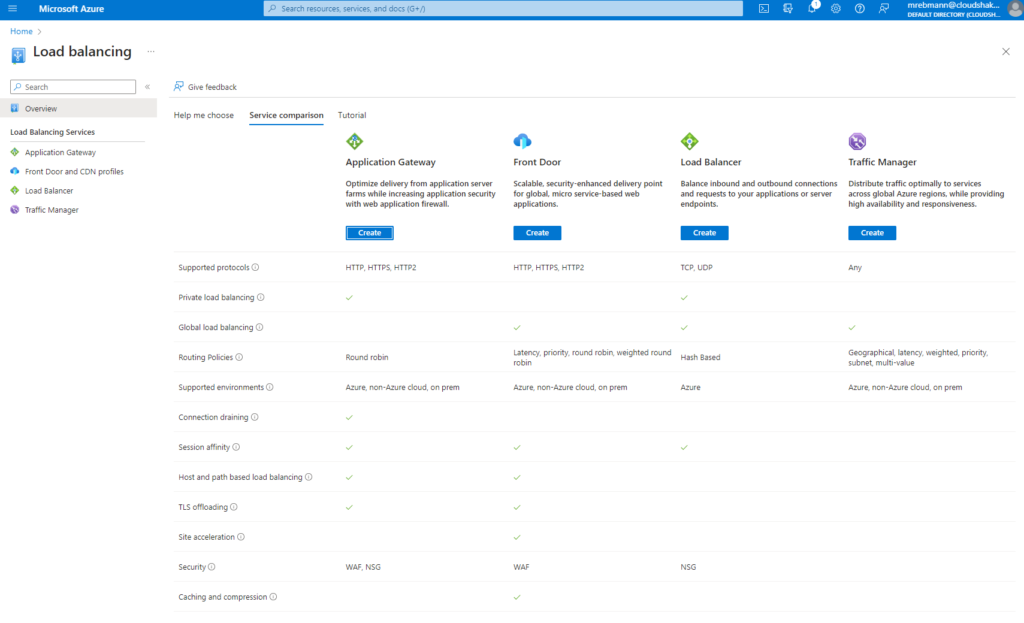
Here is a service comparison from all the load balancing options:
Global Load Balancing
Azure load-balancing services can be categorized along two dimensions: global versus regional and HTTP(S) versus non-HTTP(S).
Global vs. regional
Global: These load-balancing services distribute traffic across regional back-ends, clouds, or hybrid on-premises services. These services route end-user traffic to the closest available back-end. They also react to changes in service reliability or performance to maximize availability and performance. You can think of them as systems that load balance between application stamps, endpoints, or scale-units hosted across different regions/geographies.
Regional: These load-balancing services distribute traffic within virtual networks across virtual machines (VMs) or zonal and zone-redundant service endpoints within a region. You can think of them as systems that load balance between VMs, containers, or clusters within a region in a virtual network.
The following table summarizes the Azure load-balancing services.
Service
Global/Regional
Recommended traffic
Azure Front Door
Global
HTTP(S)
Azure Traffic Manager
Global
Non-HTTP(S)
Azure Application Gateway
Regional
HTTP(S)
Azure Load Balancer
Regional or Global
Non-HTTP(S)
Azure load-balancing services
Here are the main load-balancing services currently available in Azure:
Azure Front Dooris an application delivery network that provides global load balancing and site acceleration service for web applications. It offers Layer 7 capabilities for your application like SSL offload, path-based routing, fast failover, and caching to improve performance and high availability of your applications.
Traffic Manageris a DNS-based traffic load balancer that enables you to distribute traffic optimally to services across global Azure regions, while providing high availability and responsiveness. Because Traffic Manager is a DNS-based load-balancing service, it load balances only at the domain level. For that reason, it can’t fail over as quickly as Azure Front Door, because of common challenges around DNS caching and systems not honoring DNS TTLs.
Application Gatewayprovides application delivery controller as a service, offering various Layer 7 load-balancing capabilities. Use it to optimize web farm productivity by offloading CPU-intensive SSL termination to the gateway.
Load Balanceris a high-performance, ultra-low-latency Layer 4 load-balancing service (inbound and outbound) for all UDP and TCP protocols. It’s built to handle millions of requests per second while ensuring your solution is highly available. Load Balancer is zone redundant, ensuring high availability across availability zones. It supports both a regional deployment topology and across-region topology.
Learn about the various Azure networking services available that provide connectivity to your resources in Azure, deliver and protect applications, and help secure your network.
Virtual Networks
A virtual network cannot span regions or subscriptions, it has its boundaries, but can span (subnets) across availability zones in a region. Virtual networks are always IPv4 ranges, IPv6 ranges are optional.
Azure Virtual Network is a service that provides the fundamental building block for your private network in Azure. An instance of the service (a virtual network) enables many types of Azure resources to securely communicate with each other, the internet, and on-premises networks. These Azure resources include virtual machines (VMs).
A virtual network is similar to a traditional network that you’d operate in your own datacenter. But it brings extra benefits of the Azure infrastructure, such as scale, availability, and isolation.
Public IP addresses enable Internet resources to communicate with Azure resources and enable Azure resources to communicate outbound with Internet and public-facing Azure services. A public IP address in Azure is dedicated to a specific resource, until it’s unassigned by a network engineer. A resource without a public IP assigned can communicate outbound through network address translation services, where Azure dynamically assigns an available IP address that isn’t dedicated to the resource.
In Azure Resource Manager, apublic IP (this is also bound to a region) address is a resource that has its own properties. Some of the resources you can associate a public IP address resource with:
Virtual machine network interfaces
Virtual machine scale sets
Public Load Balancers
Virtual Network Gateways (VPN/ER)
NAT gateways
Application Gateways
Azure Firewall
Bastion Host
Route Server
Public IP addresses are created with one of the following SKUs:
Public IP address
Standard
Basic
Allocation method
Static
For IPv4: Dynamic or Static; For IPv6: Dynamic.
Idle Timeout
Have an adjustable inbound originated flow idle timeout of 4-30 minutes, with a default of 4 minutes, and fixed outbound originated flow idle timeout of 4 minutes.
Have an adjustable inbound originated flow idle timeout of 4-30 minutes, with a default of 4 minutes, and fixed outbound originated flow idle timeout of 4 minutes.
Security
Secure by default model and be closed to inbound traffic when used as a frontend. Allow traffic withnetwork security group(NSG) is required (for example, on the NIC of a virtual machine with a Standard SKU Public IP attached).
Open by default. Network security groups are recommended but optional for restricting inbound or outbound traffic.
Supported. Standard IPs can be nonzonal, zonal, or zone-redundant.Zone redundant IPs can only be created inregions where 3 availability zonesare live.IPs created before availability zones aren’t zone redundant.
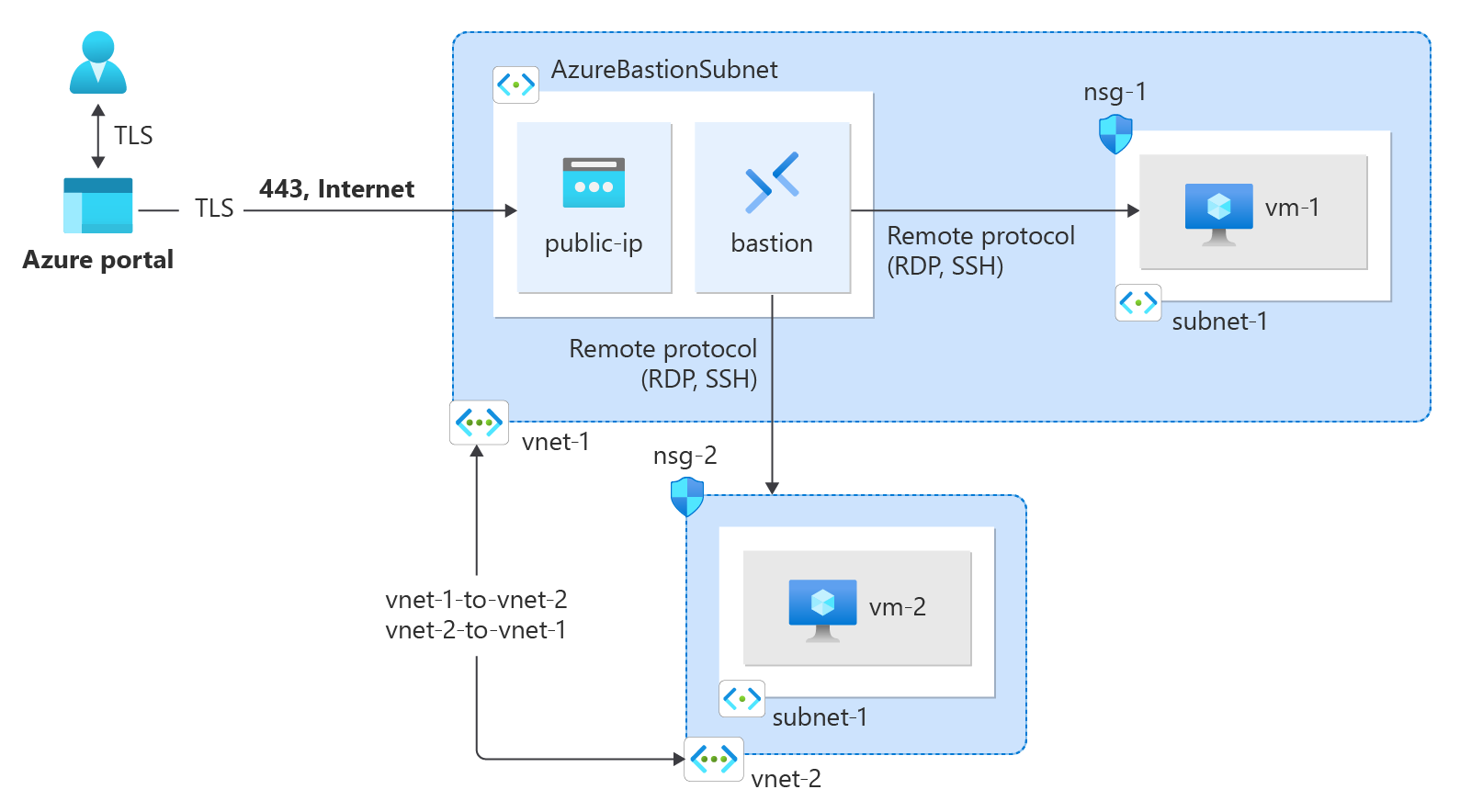
What if I have more than one network or vNets that should communicate with each other? Azure has the idea of peering that can happen in the same region or globally.
Virtual network peering enables you to seamlessly connect two or moreVirtual Networksin Azure. The virtual networks appear as one for connectivity purposes. The traffic between virtual machines in peered virtual networks uses the Microsoft backbone infrastructure. Like traffic between virtual machines in the same network, traffic is routed through Microsoft’sprivatenetwork only.
Azure supports the following types of peering:
Virtual network peering: Connecting virtual networks within the same Azure region.
Global virtual network peering: Connecting virtual networks across Azure regions.
Note: Network traffic between peered virtual networks is private. Traffic between the virtual networks is kept on the Microsoft backbone network. No public Internet, gateways, or encryption is required in the communication between the virtual networks.
Important: Peering connections are non-transitive! From the FAQ:
If I peer VNetA to VNetB and I peer VNetB to VNetC, does that mean VNetA and VNetC are peered?
No. Transitive peering is not supported. You must manually peer VNetA to VNetC.
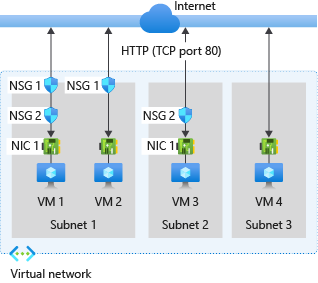
Network Security Groups
You can use an Azure network security group (NSG) to filter network traffic between Azure resources in an Azure virtual network. A network security group contains security rules that allow or deny inbound network traffic to, or outbound network traffic from, several types of Azure resources. For each rule, you can specify source and destination, port, and protocol.
A network security group contains as many rules as desired, within Azure subscriptionlimits. Each rule specifies the following properties:
Property
Explanation
Name
A unique name within the network security group. The name can be up to 80 characters long. It must begin with a word character, and it must end with a word character or with ‘_’. The name may contain word characters or ‘.’, ‘-‘, ‘_’.
Priority
A number between 100 and 4096. Rules are processed in priority order, with lower numbers processed before higher numbers, because lower numbers have higher priority. Once traffic matches a rule, processing stops. As a result, any rules that exist with lower priorities (higher numbers) that have the same attributes as rules with higher priorities aren’t processed. Azure default security rules are given the highest number with the lowest priority to ensure that custom rules are always processed first.
Source or destination
Any, or an individual IP address, classless inter-domain routing (CIDR) block (10.0.0.0/24, for example), service tag, or application security group. If you specify an address for an Azure resource, specify the private IP address assigned to the resource. Network security groups are processed after Azure translates a public IP address to a private IP address for inbound traffic, and before Azure translates a private IP address to a public IP address for outbound traffic. Fewer security rules are needed when you specify a range, a service tag, or application security group. The ability to specify multiple individual IP addresses and ranges (you can’t specify multiple service tags or application groups) in a rule is referred to asaugmented security rules. Augmented security rules can only be created in network security groups created through the Resource Manager deployment model. You can’t specify multiple IP addresses and IP address ranges in network security groups created through the classic deployment model.
Protocol
TCP, UDP, ICMP, ESP, AH, or Any. The ESP and AH protocols aren’t currently available via the Azure portal but can be used via ARM templates.
Direction
Whether the rule applies to inbound, or outbound traffic.
Port range
You can specify an individual or range of ports. For example, you could specify 80 or 10000-10005. Specifying ranges enables you to create fewer security rules. Augmented security rules can only be created in network security groups created through the Resource Manager deployment model. You can’t specify multiple ports or port ranges in the same security rule in network security groups created through the classic deployment model.
Action
Allow or deny
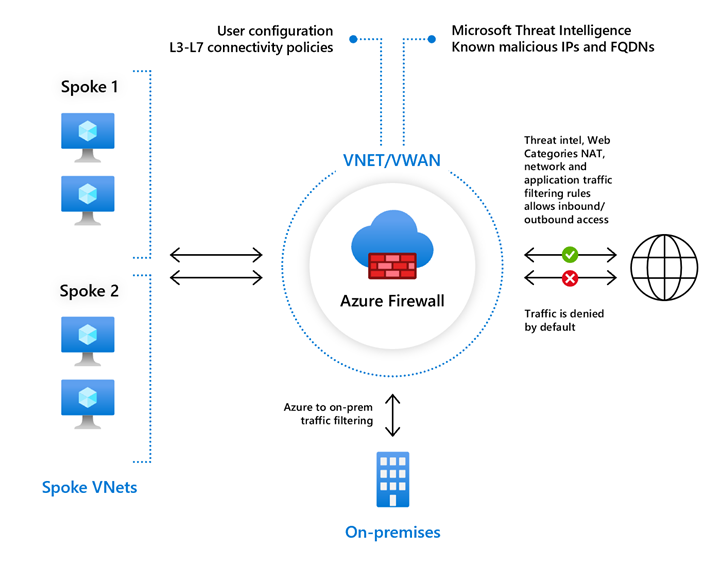
Azure Firewall and Routing
Azure Firewall is a cloud-native and intelligent network firewall security service that provides the best of breed threat protection for your cloud workloads running in Azure. It’s a fully stateful firewall as a service with built-in high availability and unrestricted cloud scalability. It provides both east-west and north-south traffic inspection. To learn what’s east-west and north-south traffic, see East-west and north-south traffic.
Azure Firewall includes the following features:
Built-in high availability
Availability Zones
Unrestricted cloud scalability
Application FQDN filtering rules
Network traffic filtering rules
FQDN tags
Service tags
Threat intelligence
DNS proxy
Custom DNS
FQDN in network rules
Deployment without public IP address in Forced Tunnel Mode
Outbound SNAT support
Inbound DNAT support
Multiple public IP addresses
Azure Monitor logging
Forced tunneling
Web categories
Certifications
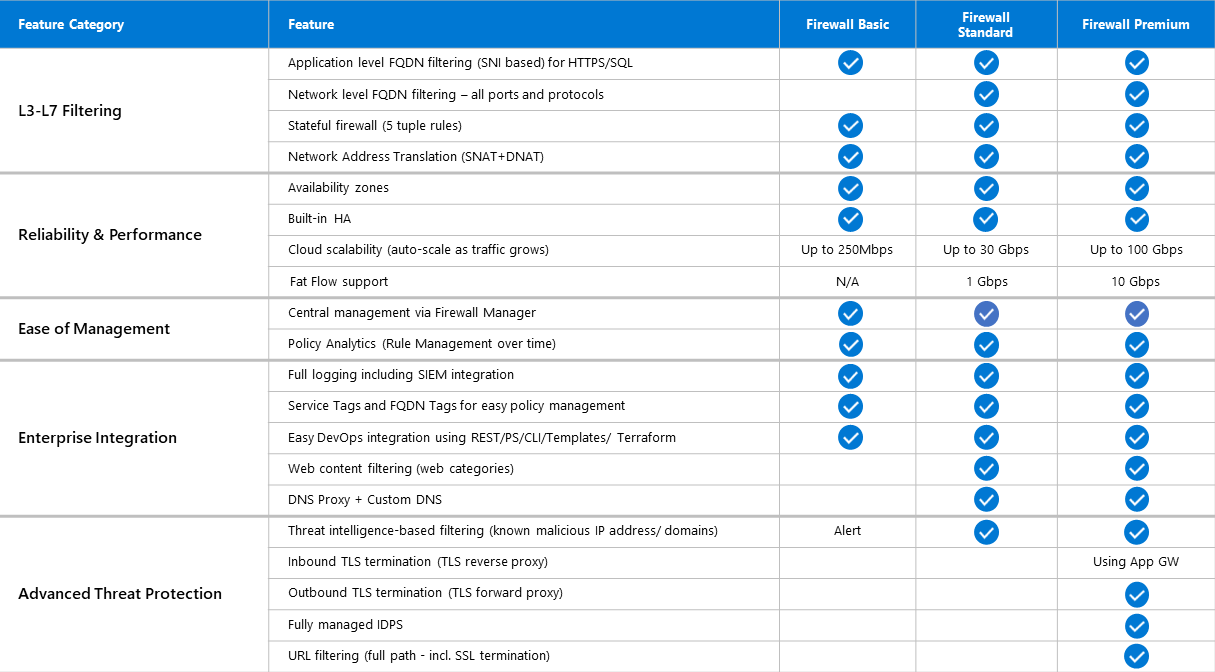
Azure Firewall now supports three different SKUs to cater to a wide range of customer use cases and preferences.
Azure Firewall Premium is recommended to secure highly sensitive applications (such as payment processing). It supports advanced threat protection capabilities like malware and TLS inspection.
Azure Firewall Standard is recommended for customers looking for Layer 3–Layer 7 firewall and needs autoscaling to handle peak traffic periods of up to 30 Gbps. It supports enterprise features like threat intelligence, DNS proxy, custom DNS, and web categories.
Azure Firewall Basic is recommended for SMB customers with throughput needs of 250 Mbps.
When I discuss a hybrid or multi-cloud architecture with my customers, especially organizations that just started to journey to the cloud, they mention the so-called cloud landing zones. I remember, a few years ago, when I asked my customers and the internal specialist what a “landing zone” is, I received an answer like this:
A landing zone is a concept or architecture, which helps you to get started with your cloud migrations based on best or leading practices. You start small, and you expand later – you put your apps in the right place.
Does this sound familiar? If everyone is saying almost the same, then there’s no need to investigate this term or definition further, right?
Since I want to better understand Azure and pass my first solutions architect exam, I thought I would google “landing zone” to check, if it’s only me who has doubts about the correct and full understanding of these so-called landing zones.
Guess what? It is almost 2024 and still a lot of people do not know exactly what landing zones are. As always, you find some content from people like John Savill and Thomas Maurer.
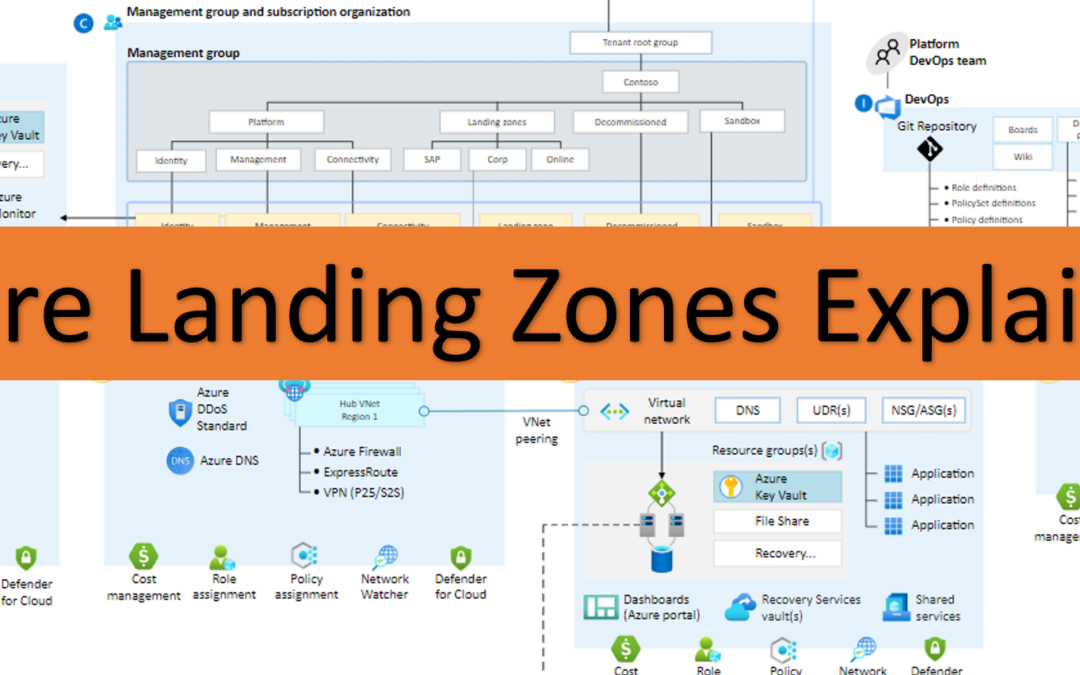
An Azure landing zone is part of the Cloud Adoption Frame (CAF) for Azure and describes an environment that follows key design principles. These design principles are about application migration, application modernization, and innovation. These landing zones use Azure subscriptions to isolate specific application and platform resources.
An Azure landing zone architecture is scalable and modular to meet various deployment needs. A repeatable infrastructure allows you to apply configurations and controls to every subscription consistently. Modules make it easy to deploy and modify specific Azure landing zone architecture components as your requirements evolve. The Azure landing zone conceptual architecture represents an opinionated target architecture for your Azure landing zone. You should use this conceptual architecture as a starting point and tailor the architecture to meet your needs.
According to Microsoft, an Azure landing zone is the foundation for a successful cloud environment.
Landing Zone Options
There are different options or approaches when it comes to the implementation of landing zones:
After studying the Azure landing zone documentation, I think my past conversations (mentioned at the beginning) were mostly about the so-called “migration landing zones”, which focus on deploying foundation infrastructure resources in Azure, that are then used to migrate virtual machines in to.
The CAF Migration blueprint lays out a landing zone for your workloads. You still need to perform the assessment and migration of your Virtual Machines / Databases on top of this foundational architecture.
Azure Landing Zones and Azure VMware Solution
If you are looking for VMware-related information about Azure VMware Solution and Azure landing zones, have a look at the following resources:
When you browse through the Azure documentation, you will find out that Azure landing zones have two different kinds of subscriptions:
Platform landing zone: A platform landing zone is a subscription that provides shared services (identity, connectivity, management) to applications in application landing zones. Consolidating these shared services often improves operational efficiency. One or more central teams manage the platform landing zones. In the conceptual architecture (see figure 1), the “Identity subscription”, “Management subscription”, and “Connectivity subscription” represent three different platform landing zones. The conceptual architecture shows these three platform landing zones in detail. It depicts representative resources and policies applied to each platform landing zone.
There’s a ready-made deployment experience called the Azure landing zone portal accelerator. The Azure landing zone portal accelerator deploys the conceptual architecture and applies predetermined configurations to key components such as management groups and policies. It suits organizations whose conceptual architecture aligns with the planned operating model and resource structure.
Application landing zone: An application landing zone is a subscription for hosting an application. You pre-provision application landing zones through code and use management groups to assign policy controls to them. In the conceptual architecture, the “Landing zone A1 subscription” and “Landing zone A2 subscription” represent two different application landing zones. The conceptual architecture shows only the “Landing zone A2 subscription” in detail. It depicts representative resources and policies applied to the application landing zone.
Application landing zone accelerators help you deploy application landing zones.
Review your Azure platform readiness so adoption can begin, and assess your plan to create a landing zone to host workloads that you plan to build in or migrate to the cloud. This assessment is designed for customers with two or more years experience. If you are new to Azure, this assessment will help you identify investment areas for your adoption strategy.
AWS defines a landing zone as a “well-architected, multi-account AWS environment that is scalable and secure“. An AWS or Azure landing zone is a starting point from which customers can quickly launch and deploy workloads and apps with the right security and governance in mind and in place. It is not about technical decisions only, but it also involves business decisions to be made about account structure, identities, networking, access management, and security with an organization’s growth and business goals for the future.
Landing zones have a lot to do with the right guardrails and policies in place.
Even though I took the Azure Fundamentals exam a long time ago, I think it is always helpful and important to repeat the Azure basics. Believe or not, a lot of (IT) folks still have to learn the foundations and hopefully this summary is helpful for some of you.
Microsoft has datacenter around the world. If you go to https://datacenters.microsoft.com/globe/explore one can see and explore Azure’s global infrastructure. This means that the Azure cloud consists of hundreds of unique physical buildings all over the globe to provide compute, storage, networking, and many other services.
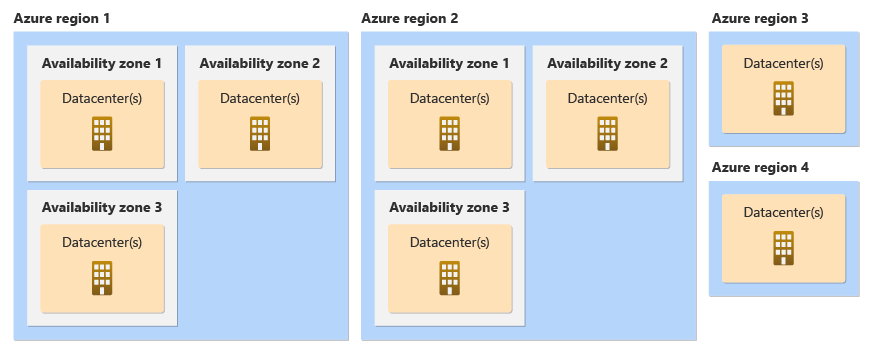
Regions
A specific set of datacenters deployed within a latency-defined perimeter is called a region. Each region comes with a different pricing and service availability.
Many regions also have a paired region. Paired regions support certain types of multi-region deployment approaches. Some newer regions have multiple availability zones and don’t have a paired region. You can still deploy multi-region solutions into these regions, but the approaches you use might be different.
Regions without a pair will not have geo-redundant storage (GRS). Such regions follow data residency guidelines to allow for the option to keep data resident within the same region. Customers are responsible for data resiliency based on their Recovery Point Objective or Recovery Time Objective (RTO/RPO) needs and may move, copy, or access their data from any location globally. In the rare event that an entire Azure region is unavailable, customers will need to plan for their Cross Region Disaster Recovery.
The table below lists Azure regions without a region pair:
Geography
Region
Qatar
Qatar Central
Poland
Poland Central
Israel
Israel Central
Italy
Italy North
Austria
Austria East (Coming soon)
Spain
Spain Central (Coming soon)
Availability Zones
Each region has multiple availability zones (AZ) which allow customers to distribute their infrastructure and workloads/applications across different datacenters for resiliency and high availability (=reliability) purposes.
Note: If you know which apps do not need 100% high availability during certain periods of time, you can optimize costs during those non-critical periods.
Zonal and Zone-redundant Services
There are two ways that Azure services use availability zones:
Zonalresources are pinned to a specific availability zone. You can combine multiple zonal deployments across different zones to meet high reliability requirements. You’re responsible for managing data replication and distributing requests across zones. If an outage occurs in a single availability zone, you’re responsible for failover to another availability zone.
Zone-redundantresources are spread across multiple availability zones. Microsoft manages spreading requests across zones and the replication of data across zones. If an outage occurs in a single availability zone, Microsoft manages failover automatically.
Azure services support one or both of these approaches. Platform as a service (PaaS) services typically support zone-redundant deployments. Infrastructure as a service (IaaS) services typically support zonal deployments.
Azure Edge Zones
These small-footprint extensions of Azure are place in population centers that are far from Azure regions.
Azure public MEC integrates Azure Compute and edge-optimized Azure services with the mobile operator’s public 5G network connectivity. Use the solution to rapidly develop and deliver a broad array of low-latency applications and solve critical business problems at the operator edge.
SLA on Azure
Microsoft commits to defined uptime numbers for different services:
An organization represents a business entity that is using Microsoft cloud offerings, typically identified by one or more public Domain Name System (DNS) domain names, such as contoso.com. The organization is a container for subscriptions.
Subscriptions
A subscription is an agreement with Microsoft to use one or more Microsoft cloud platforms or services, for which charges accrue based on either a per-user license fee or on cloud-based resource consumption.
Microsoft’s Software as a Service (SaaS)-based cloud offerings (Microsoft 365 and Dynamics 365) charge per-user license fees.
Microsoft’s Platform as a Service (PaaS) and Infrastructure as a Service (IaaS) cloud offerings (Azure) charge based on cloud resource consumption.
User Accounts
User accounts for all of Microsoft’s cloud offerings are stored in a Microsoft Entra tenant, which contains user accounts and groups. A Microsoft Entra tenant can be synchronized with your existing Active Directory Domain Services (AD DS) accounts using Microsoft Entra Connect, a Windows server-based service. This is known as directory synchronization.
Summary of the Hierarchy
Here is a quick recap:
An organization can have multiple subscriptions
A subscription can have multiple licenses
Licenses can be assigned to individual user accounts
User accounts are stored in a Microsoft Entra tenant
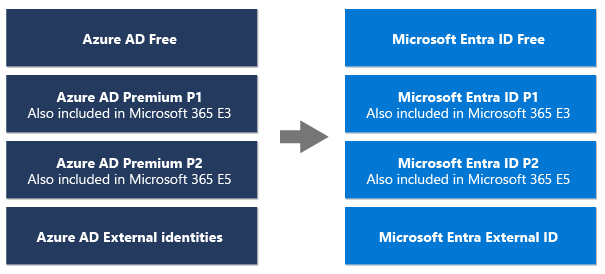
What is Microsoft Entra ID?
Microsoft Entra ID, formerly known as Azure Active Directory (AAD), is a cloud-based identity and access management service that enables your employees access external resources. Example resources include Microsoft 365, the Azure portal, and thousands of other SaaS applications.
Microsoft has renamed Azure Active Directory (Azure AD) to Microsoft Entra ID for the following reasons: (1) to communicate the multicloud, multiplatform functionality of the products, (2) to alleviate confusion with Windows Server Active Directory, and (3) to unify the Microsoft Entra product family.
Microsoft Entra ID is the new name for Azure AD. The names Azure Active Directory, Azure AD, and AAD are replaced with Microsoft Entra ID.
Microsoft Entra is the name for the product family of identity and network access solutions.
Microsoft Entra ID is one of the products within that family.
Acronym usage is not encouraged, but if you must replace AAD with an acronym due to space limitations, use ME-ID.
Microsoft Entra ID also helps them access internal resources like apps on your corporate intranet, and any cloud apps developed for your own organization.
Microsoft Online business services, such as Microsoft 365 or Microsoft Azure, use Microsoft Entra ID for sign-in activities and to help protect your identities. If you subscribe to any Microsoft Online business service, you automatically get access toMicrosoft Entra ID Free.
My name is Michael Rebmann. I work as Public Sector & Service Provider Lead Switzerland at Nutanix, where I help public sector and service provider organizations build sovereign and compliant cloud infrastructures. I focus on sovereign cloud, hybrid multi-cloud architectures, and data privacy in regulated industries.
The views and opinions expressed here are entirely my own, reflecting my journey and insights.






 Note:
Note: