VMware Cloud Foundation Spotlight – February 2024
I remember during all those years when I told customers that “VMware Cloud Foundation is the new vSphere”, and in my opinion, Broadcom is preparing the way that VMware Cloud Foundation (VCF) becomes long-term the new de facto standard in data centers (and public clouds). With this first spotlight, I would like to highlight some of the new information from VMware by Broadcom.
End of General Availability of the Free vSphere Hypervisor
In case you missed the information in the blog VMware End Of Availability of Perpetual Licensing and SaaS Services:
There is no “replacement product” for the “VMware vSphere Hypervisor free edition”. The recently published KB2107518 confirms it:
As part of the transition of perpetual licensing to new subscription offerings, the VMware vSphere Hypervisor (Free Edition) has been marked as EOGA (End of General Availability). At this time, there is not an equivalent replacement product available.
VMware Data Services Strategy
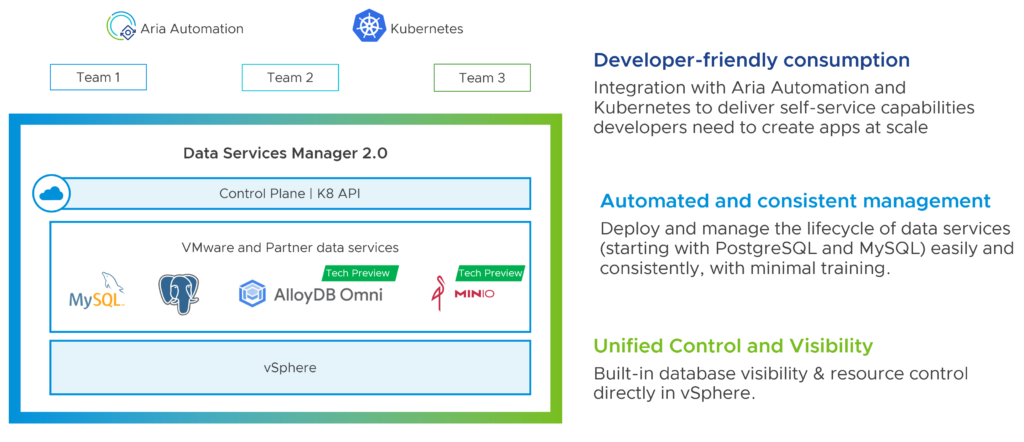
VMware announced at VMware Explore 2023 that Data Services Manager 2.0 (DSM 2.0) is going to be a key component of their strategy and that it will be tightly integrated with VMware Cloud Foundation. Back in November, VMware expected the next generation of DSM to be available in Q4 FY24 (aka Q1 calendar year 2024 for us), which would be soon.
In response to a growing need from customers to deliver and support next-gen cloud native and AI-powered applications in their private cloud, we are now including Data Services Manager in VMware Cloud Foundation to deliver a native infrastructure automation and management experience for data services.
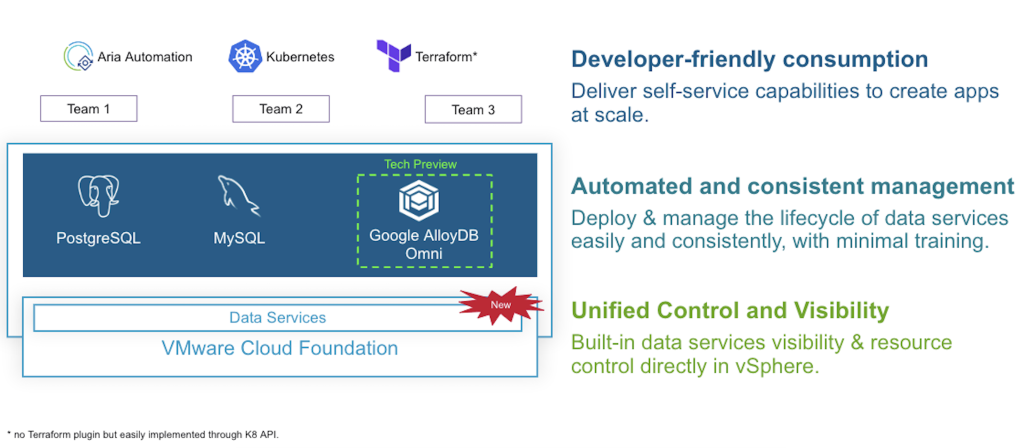
Learn more about DSM 2.0 on Cormac Hogan’s blog: https://cormachogan.com/dsm/
Important: Data Services Manager is available for VCF customers only.
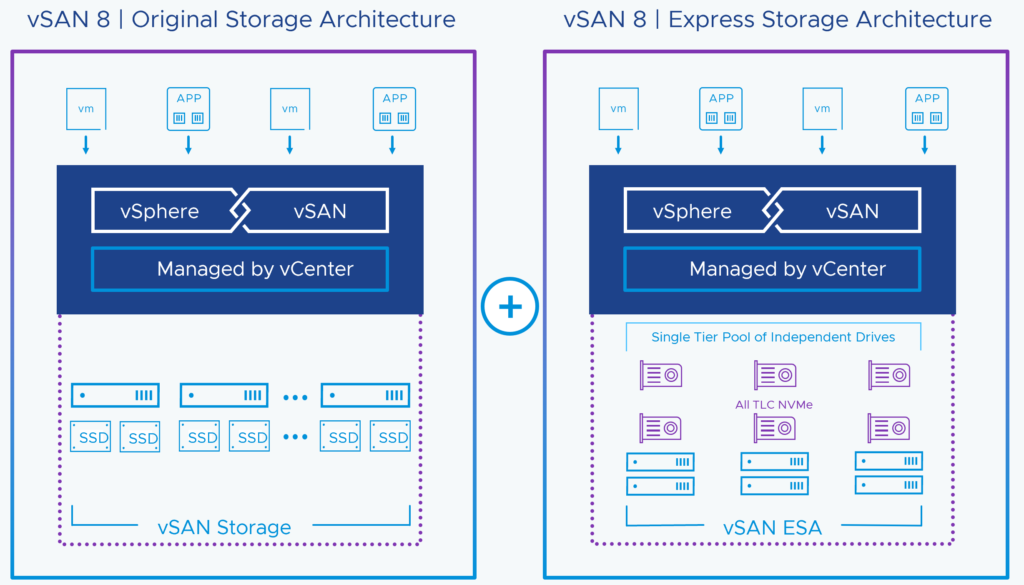
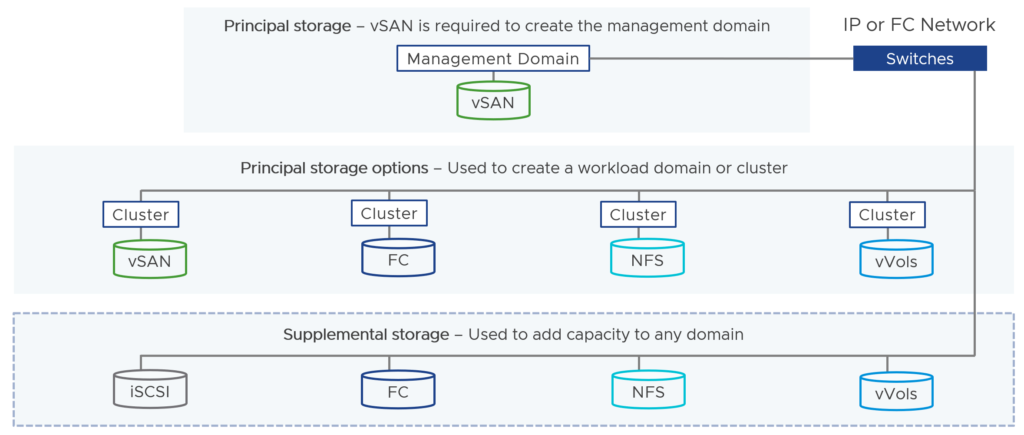
VCF – vSAN Capacity
The script and license calculator from VMware show no more 8 TiB minimum requirement per CPU socket. Have not seen any official announcement yet.
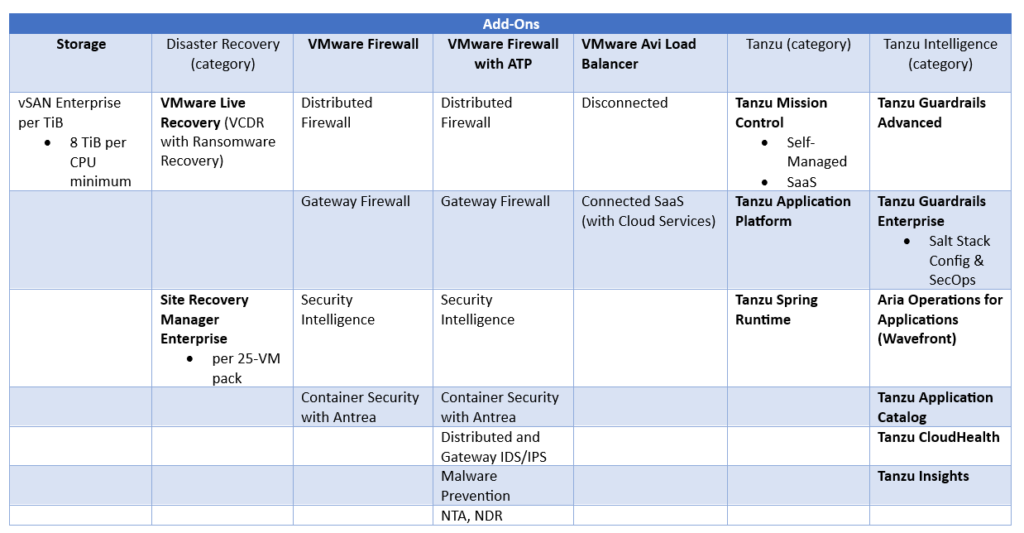
Any news about the VMware Firewall and VMware Firewall with ATP add-ons?
No. It is still the case that customers, who need NSX’s distributed firewall or ATP (advanced threat prevention) capabilities, need to purchase these add-ons to VCF. In other words, you need to have VMware Cloud Foundation and you cannot get these add-ons as standalone products independently from VCF.
ROBO and Edge Compute Stack
VMware announced last week two new Edge Compute Stack (ECS) editions:
- ECS Advanced Edition: VMware Edge Cloud Orchestrator (VECO), VMware vSphere Foundation (VVF)
- ECS Enterprise Edition: VECO, VMware Cloud Foundation (VCF)
This is not a replacement for ROBO customers and use cases, but the new ECS offerings are specially made for edge use cases and hence might be the right solution for your needs.
Important: Not all VVF and VCF products and features are included in the ECS Editions. Example: With ECS Enterprise customers will manage their environments with VECEO instead of using SDDC Manager.
What happens if my VVF or VCF subscriptions expire?
The new subscription licenses customers get, have no expiration date. An expiring license should have no impact on your infrastructure, deployed VMware products continue to run as expected. After expiration, customers will not be able to receive support.
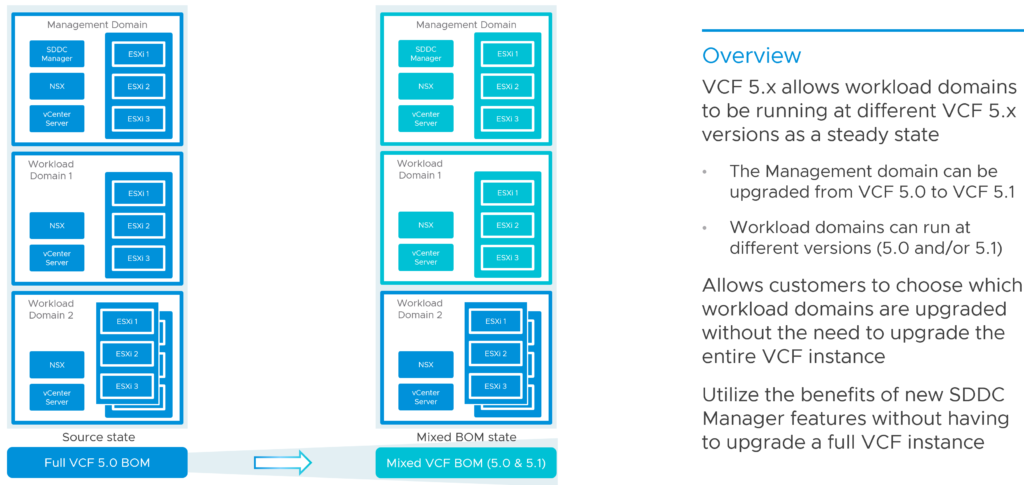
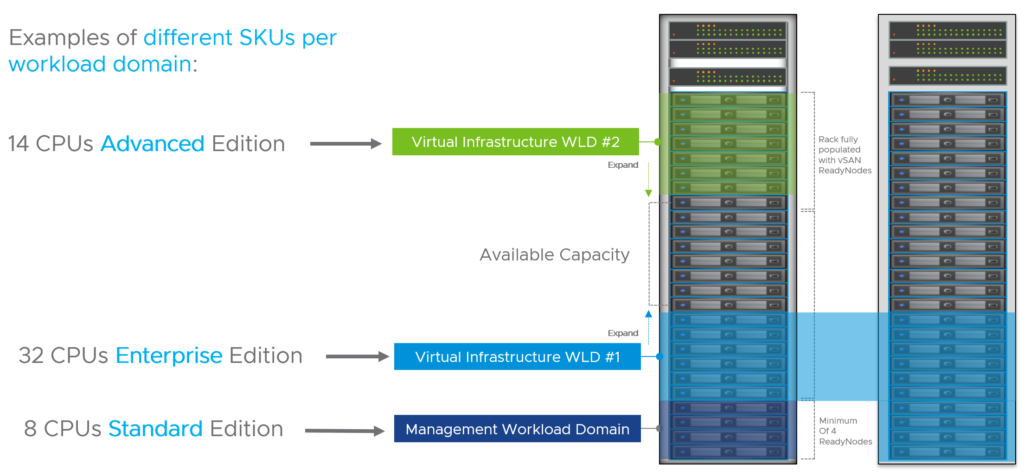
VMware Cloud Foundation – What is a Workload Domain?
https://www.youtube.com/watch?v=kwn1fqb3lts&ab_channel=VMwareCloudFoundation
Updated VMware Cloud Foundation Datasheet
We finally can find an updated VCF datasheet here.
What happened to the Avi Basic Edition?
It looks like the NSX Advanced Load Balancer (ALB) Basic Edition is not available anymore.
VMware is announcing the End of Availability of NSX Advanced Load Balancer (ALB) Basic Edition for new deployments and End of General Support (EoGS) for existing deployments.
Note: NSX ALB is now referred to as VMware Avi Load Balancer.
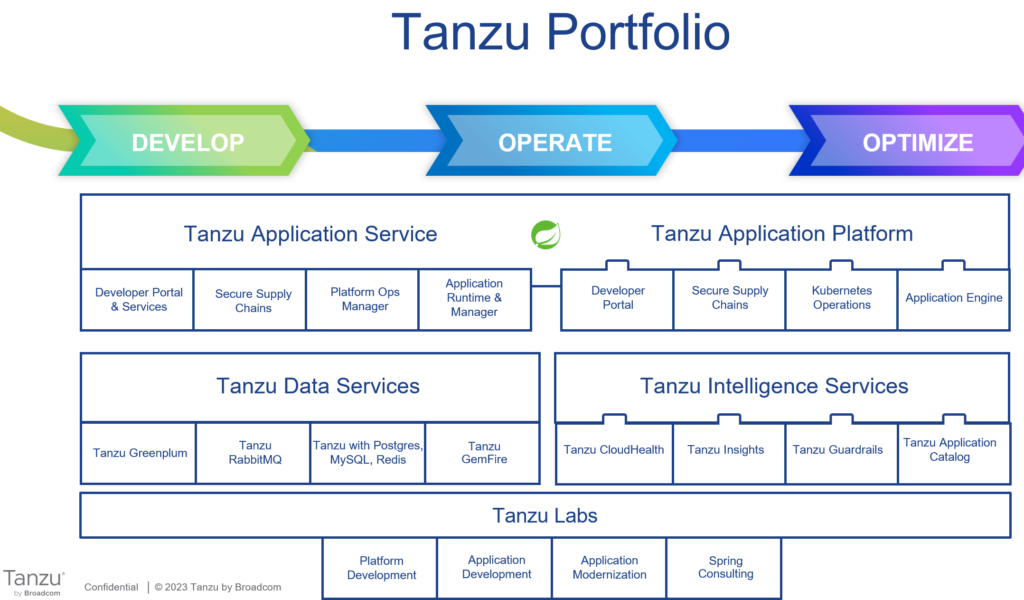
What about the future of Tanzu Kubernetes Grid (TKG)?
Please ask your VMware contact to organize a meeting with Timmy Carr, who can share more information about the TKG roadmap.
Hint: The roadmap for this year looks VERY promising!
Is VMware by Broadcom working on a VCF roadmap?
Yes, definitely. While I am not allowed to share any detailed information, here are some items my customers have on their wishlist:
- Easier deployment and lifecycle management
- Brownfield support (import existing vSphere, vSAN, NSX and Aria deployments)
- Improvement of authentication and single sign-on
- Decouple TKG and Kubernetes releases from vCenter
- Include AI and cybersecurity capabilities
- Reduce the number of needed VMware appliances
- Single license and same version numbers for all VCF components
- Improve certification management in all products
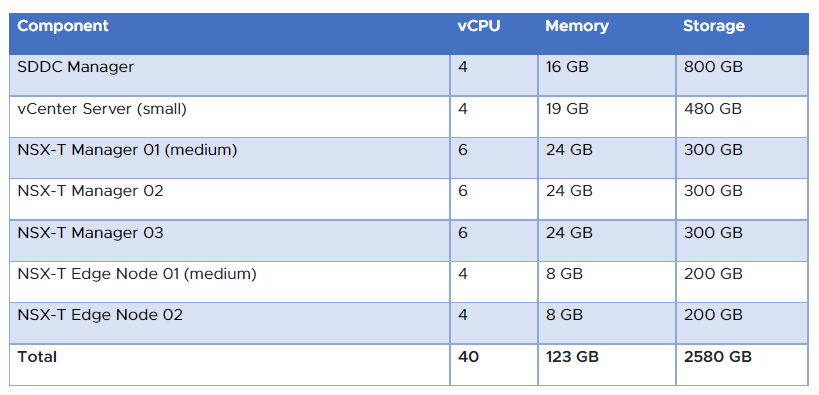
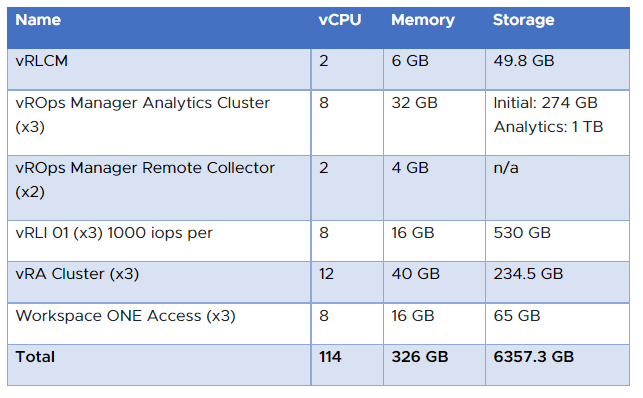
Note: In case you are looking for more technical information about VMware Cloud Foundation, have a look at my most recent technical overview.
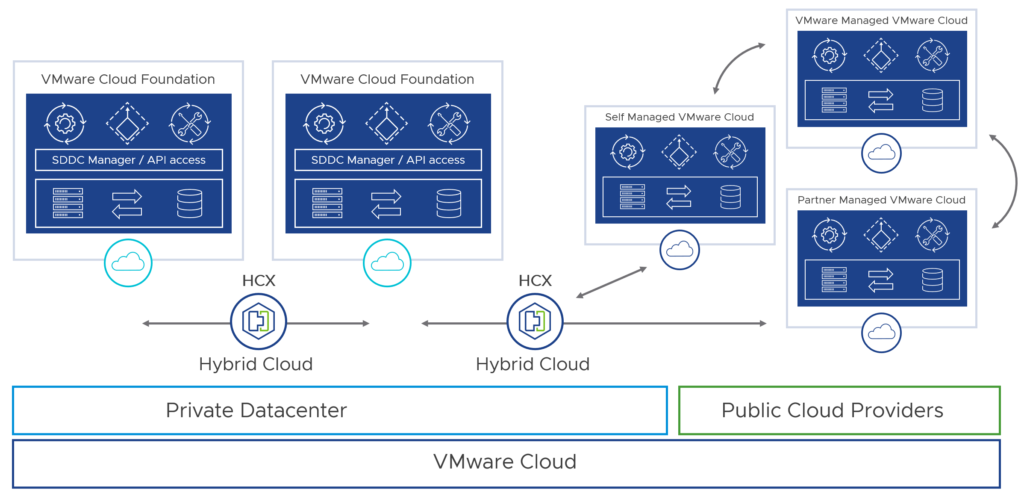
VMware Cloud on AWS – Advanced Security Features
Let us talk about VMware Cloud now since we have not heard that much about it during the past months.
Today, we are happy to announce that to address these challenges, we are providing some advanced security features out of the box as part of VMware Cloud on AWS core service. Now customers can strengthen the security posture of their hybrid cloud infrastructure with advanced security capabilities such as Layer 7 Application ID, FQDN Filtering, and User Identity-based Firewall (IDFW). Starting Feb 1, 2024, these features are available at no extra cost in all the SDDCs (new and existing SDDCs). These features are available via VMware Direct as well as AWS Resell routes to market.
All customers will be automatically entitled to the advanced security features on Feb 1, 2024. To avail these features, customers simply need to activate the ‘NSX Advanced Firewall’ service from the Integrated Services Tab under the NSX Advanced Firewall tile on VMware Cloud Console.
Google Cloud VMware Engine License Portability
VMware by Broadcom announced in December 2023 that they are working on license portability and a bring-your-own-license model for VMware Cloud.
From now on customers will be able to purchase subscriptions of the new VMware Cloud Foundation software from Broadcom and flexibly use those subscriptions in Google Cloud VMware Engine, as well as their on-premises data centers. Customers will retain the rights to the software subscription when deploying VMware Cloud Foundation on Google Cloud VMware Engine and have the ability to move their subscription between supported environments as desired.
Google Cloud is the first partner that is going to support VMware Cloud Foundation license portability!
Note: Broadcom and Google Cloud expect VMware Cloud Foundation license portability to Google Cloud VMware Engine to be available publicly in the second quarter of the calendar year 2024.
Azure VMware Solution
The partnership with Microsoft continues under VMware by Broadcom: https://azure.microsoft.com/en-us/blog/continued-innovation-with-azure-vmware-solution/
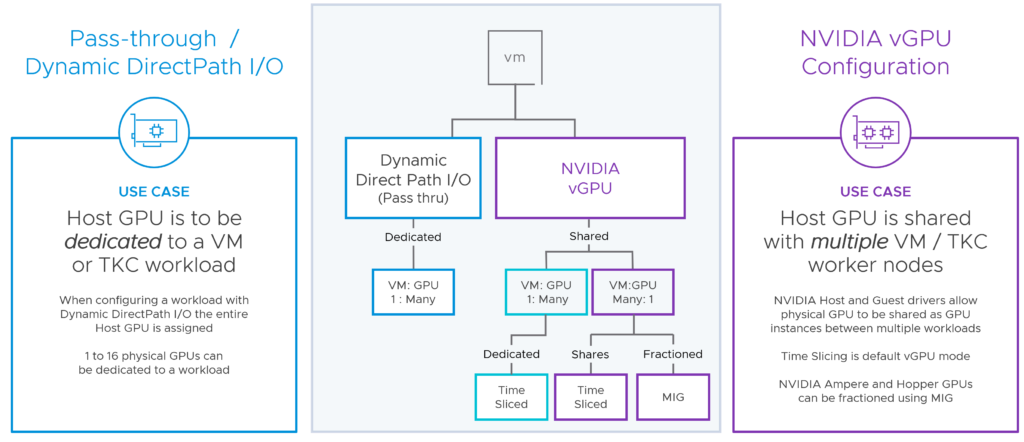
VMware Private AI Foundation with NVIDIA
VMware Private AI Foundation will become available this quarter. In the meanwhile, have a look at this IDC whitepaper about “For Generative AI, Private Data Is the Differentiator But Poses Security Concerns“.