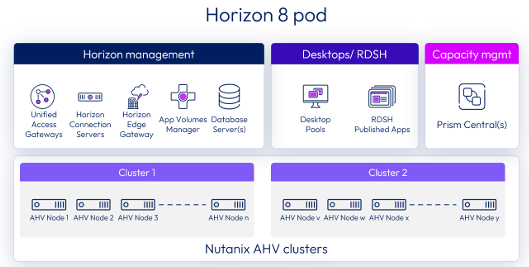
Nutanix’s EUC Stack Reduces TCO and Improves ROI
Virtual Desktop Infrastructure (VDI) has always been a conservative technology. It sits close to users, productivity, and operational risk. For years, the dominant conversation revolved around brokers, protocols, and user experience. Today, that conversation is shifting more towards licensing, platform dependency, roadmap uncertainty and support models. Even product availability is becoming the real driver behind VDI decisions.
The recent announcements from Omnissa clearly reflect this shift. Horizon 8 is now generally available on Nutanix AHV, opening a long-awaited alternative virtualization path for enterprise-grade VDI.
VMware vSphere Foundation for VDI (VVF for VDI)
The combined Omnissa Horizon and VMware vSphere Foundation for VDI offering responds to a very real customer desire for simplification. For organizations already standardized on VMware technologies, fewer contracts and a predefined bundle feel familiar and operationally convenient.
Broadcom has announced the discontinuation of VMware vSphere Foundation in specific countries and regions, most notably in parts of EMEA. The decision does not apply globally (yet), but it is explicit, regional, and commercially binding for affected markets. Availability is no longer uniform, and customers must now verify on a country-by-country basis whether VMware vSphere Foundation (VVF) can still be procured.
It is important to be precise, though. The recent discontinuation of VVF applies only to specific countries and, as of today, it seems it does not include VVF for VDI for existing Omnissa customers. Horizon customers can still consume VVF for VDI in those environments, and there has been no formal announcement that this specific bundle will be withdrawn.
At the same time, it would be naive to ignore the broader context. VVF for VDI ultimately depends on the commercial and strategic relationship between Omnissa and Broadcom. Omnissa does not fully control the underlying hypervisor roadmap, its regional availability, or future sales policies. Any material change requires negotiation between two vendors with different priorities and incentives.
Currently, VVF for VDI, which can be bundled with Horizon, includes vSphere 8. Support for the vSphere portion of the bundle will continue to be provided by VMware by Broadcom. The bundled offerings are available to be purchased in up to 5-year terms (restrictions may apply). Subject to their general terms, Broadcom/VMware will provide vSphere 8 for the period of the license that a customer has purchased. Broadcom has not yet announced timelines for vSphere 9 support with VVF for VDI. We are working with Broadcom to enable VVF for VDI in an upcoming vSphere 9.x release, but no date has yet been committed. If a customer has a current requirement to move to vSphere 9, they will need to buy VCF or VVF separately from Broadcom.
Recent decisions around VVF in parts of EMEA illustrate this clearly. Even if VVF for VDI remains available today, customers are implicitly betting on the continued alignment between Omnissa and Broadcom. Packaging may simplify procurement in the short term, but it also concentrates dependency at the most critical layer of the stack. For VDI environments, where stability and predictability are non-negotiables, this dependency becomes an integral part of the risk assessment.
Why This Context Matters for NCI-VDI
This is where Nutanix Cloud Infrastructure for VDI starts to look less like an alternative and more like a structurally safer choice.
With Horizon supported on AHV, customers can decouple broker choice from hypervisor dependency. But the value goes beyond commercial optionality. It also shows up in how the platform behaves operationally.
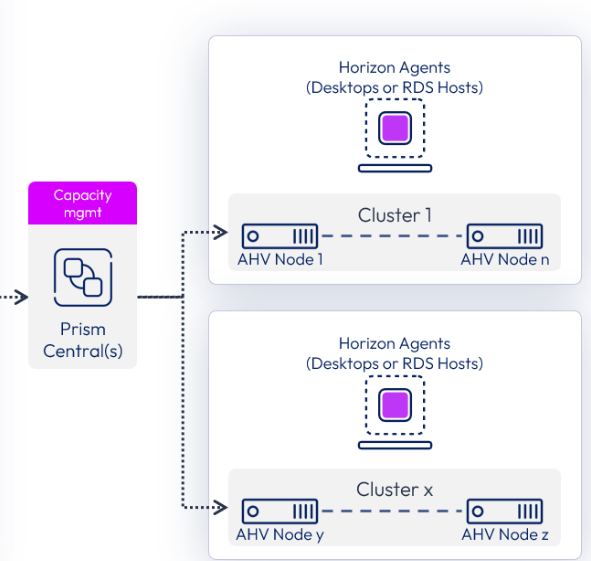
Enhanced refresh workflows introduce recovery points for desktop refresh operations. Instead of rebuilding or troubleshooting desktops under pressure, IT teams gain a practical rollback mechanism. It is essentially an undo button for virtual desktops, reducing downtime, simplifying remediation, and improving resilience for business continuity scenarios.
GPU-accelerated VDI is another area where the platform advantage becomes tangible. Managed NVIDIA vGPU support is integrated into compute profiles for Horizon workloads. GPU profiles are no longer an afterthought or a separate administrative domain. This makes it significantly easier to deliver high-performance virtual workstations for AI, design, healthcare imaging, or analytics workloads, while reducing operational complexity for administrators.
For environments relying on RDSH, NCI-VDI now brings full automation for farms, published desktops, and applications. Farm creation, scaling, and app publishing no longer require manual orchestration.
ClonePrep customization completes the picture. Virtual machines can be customized rapidly during pool or farm creation, giving IT teams precise control over how desktops are initialized. Configurations remain consistent across pools, while still allowing organizational requirements to be enforced centrally.
These are the current Nutanix configuration maximums for AHV:
- Cluster size – The maximum AHV hosts per cluster is 32
- VMs per host – The maximum powered on VDI VMs per AHV node is 200.
- VMs per cluster – The maximum number of powered-on VMs per AHV cluster is 4096.
Note: The Horizon 8 reference architecture for AHV deployments is available here.
Licensing That Reflects How VDI Is Actually Used
Licensing discussions around VDI often focus narrowly on user counts and price points. What is frequently overlooked is what is not included, as well as the architectural assumptions that are quietly embedded in the bundle.
VVF for VDI, whether consumed by Omnissa Horizon customers or Citrix customers (regular VVF), does not include NSX and its distributed firewalling capabilities. Network micro-segmentation, east-west traffic control, and fine-grained security policies are not part of the VVF for VDI entitlement. Customers that require these capabilities must either accept architectural gaps or upgrade to VMware Cloud Foundation (VCF).
NCI-VDI approaches this differently, particularly in the Ultimate edition. Licensing remains per concurrent user, pooled and based on the highest usage, but the functional scope expands in a way that directly impacts architecture and resilience.
With NCI-VDI Ultimate, customers gain native micro-segmentation capabilities as part of the platform. Security is enforced at the workload level without relying on an external networking stack or add-on products. For VDI environments, especially in regulated or multi-tenant scenarios, this enables consistent isolation between desktop pools, user groups, and supporting services without introducing operational complexity.
Replication and availability are another area where licensing and architecture intersect. NCI-VDI Ultimate includes advanced replication capabilities, including metro availability as well as Async DR and NearSync replication.
The key point here is alignment. Licensing reflects how VDI is actually used in production, including security boundaries within the platform, continuous availability expectations, and the need to protect stateful desktops without redesigning the entire environment. When these capabilities are included by design, TCO becomes more predictable and ROI improves over the full lifecycle.
Storage Included
User data has always been one of the hidden cost drivers in VDI projects. Profiles, documents, shared data, and application artifacts often introduce additional products, licenses, and operational silos.
With NCI-VDI, up to 100 GiB of Nutanix Unified Storage (NUS) per user is included and pooled. Home directories, profile data, shared file services, or other workloads can all be covered without introducing a separate storage platform.
Nutanix Unified Storage (NUS) is a software-defined storage platform consolidating file, object, and block storage into a single platform. Integrated with Nutanix hyperconverged infrastructure (HCI), NUS enhances the security and performance of virtual desktops and applications, while simplifying administration of storage. Your team can easily manage and control all file, object, and block data in one place—both on-premises and in the cloud such as AWS and Azure.
Again, fewer products and fewer operational boundaries translate directly into lower TCO.
Support Models Matter When VDI Becomes Business-Critical
Support is rarely part of the initial VDI design discussion. It usually becomes relevant when something breaks or when an upgrade behaves differently than expected.
In the VMware vSphere Foundation model, support is typically delivered through distributors and channel partners. While many partners do excellent work, this structure introduces an additional layer between the customer and the platform vendor. When issues span multiple layers, including broker, hypervisor, and storage, responsibility can become fragmented.
With NCI-VDI, customers running Horizon or Citrix on AHV engage directly with Nutanix for the infrastructure layer. Compute, storage, and virtualization are owned by a single support organization with a Net Promoter Score (NPS) consistently above 90.
Fewer handoffs, faster root-cause analysis, and clearer accountability directly improve operational efficiency and ROI.
Compliance Without Disruption – A Public-Sector Perspective
For healthcare organizations and federal agencies, licensing compliance is a continuity topic. Clinical systems and public services cannot be interrupted because of a licensing issue.
With NCI-VDI, license enforcement preserves operational continuity. Existing workloads continue to run even if a customer temporarily falls out of compliance. There is no forced shutdown and no service interruption.
Restrictions apply elsewhere, such as cluster expansion, access to support, management UIs, or upgrades and patches. Compliance remains enforceable, but without turning it into an operational incident. For public sector environments, this behavior is essential.
Closing Thought
VDI is no longer just about delivering desktops and virtual applications. It has become a platform decision that directly affects cost control, resilience, compliance, and long-term autonomy. Combined offerings like VVF for VDI may simplify procurement in the short term, but they also increase dependency at the most critical layer of the stack, a layer that recent changes have shown can shift regionally, commercially, and strategically.
Nutanix does not force customers into a single broker strategy, Horizon runs on AHV and Citrix remains a long-standing partner. The broker is important, but it is not where most long-term cost, risk, and complexity accumulate. The real differentiation lies below the broker layer.
When compute, storage, virtualization, security, and availability are delivered as one integrated platform, TCO drops almost naturally. Fewer vendors reduce dependency risk, and fewer dependencies reduce roadmap uncertainty. Lastly, fewer handoffs reduce operational friction. Together, these effects compound over time and translate directly into a higher return on investment.
Nutanix NCI-VDI gives customers the freedom to decouple the broker choice from hypervisor dependency, embedding security and availability into the platform, and aligning licensing with how VDI is actually used in production, it reduces TCO in ways that only become fully visible over multiple renewal cycles.