Oracle Cloud Infrastructure 2025 Networking Professional Study Guide
When I first stepped into the world of cloud networking, it wasn’t through Oracle, AWS, or Azure. It was about 13 years ago, working at a small cloud service provider that ran its own infrastructure stack. We didn’t use hyperscale magic, we built everything ourselves.
Our cloud was stitched together with VMware vCloud Director, Cisco Nexus 1000v, physical Cisco routers and switches, and a good amount of BGP. We managed our own IP transits, IP peerings, created interconnects, configured static and dynamic routing, and deployed site-to-site VPNs for customers.
Years later, after moving into cloud-native networking and skilling up on Oracle Cloud Infrastructure (OCI), I realized how many of the same concepts apply, but with better tools, faster provisioning, and scalable security. OCI offers powerful services for building modern network topologies: Dynamic Routing Gateways, Service Gateways, FastConnect, Network Firewalls, and Zero Trust Packet Routing (ZPR).
This study guide is for anyone preparing for the OCI 2025 Networking Professional certification.
Exam Objectives
Review the exam topics:
- Design and Deploy OCI Virtual Cloud Networks (VCN)
- Plan and Design OCI Networking Solutions and App Services
- Design for Hybrid Networking Architectures
- Transitive Routing
- Implement and Operate Secure OCI Networking and Connectivity Solutions
- Migrate Workloads to OCI
- Troubleshoot OCI Networking and Connectivity Issues
VCN – Your Virtual Cloud Network
Think of a VCN as your private, software-defined data center in the cloud. It is where everything begins. Subnets, whether public or private, live inside it. You control IP address ranges (CIDRs), route tables, and security lists, which together determine who can talk to what and how. Every other networking component in OCI connects back to the VCN, making it the central nervous system of your cloud network.
Internet Gateway – Letting the Outside World In (and Out)
If your VCN needs to connect to the public internet – say, to allow inbound HTTP traffic to a web server or to allow your compute instances to fetch updates – you’ll need an Internet Gateway. It attaches to your VCN and enables this connectivity.

But it is just one piece of the puzzle. You still need to configure route tables and security rules correctly. Otherwise, traffic won’t flow.
Local Peering Gateway – Talking Across VCNs (in the Same Region)
When you have got multiple VCNs in the same OCI region, maybe for environment isolation or organizational structure, a Local Peering Gateway (LPG) allows them to communicate privately. No internet, no extra costs. Just fast, internal traffic. It’s especially useful when designing multi-VCN architectures that require secure east-west traffic flow within a single region.

Dynamic Routing Gateway – The Multi-Path Hub
The Dynamic Routing Gateway (DRG) is like the border router for your VCN. If you want to connect to on-prem via VPN, FastConnect, or peer across regions, you’re doing it through the DRG. It supports advanced routing, enables transitive routing, and connects you to just about everything external. It’s your ticket to hybrid and multi-region topologies.
Remote Peering Connection – Cross-Region VCN Peering
Remote Peering Connections (RPCs) let you extend your VCN communication across regions. Let’s say you have got a primary environment in US East and DR in Germany, you’ll need a DRG in each region and an RPC between them. It’s all private, secure, and highly performant. And it’s one of the foundations for multi-region, global OCI architectures.

Note: Without peering, a given VCN would need an internet gateway and public IP addresses for the instances that need to communicate with another VCN in a different region.
Service Gateway – OCI Services Without Public Internet
The Service Gateway is gold! It allows your VCN to access OCI services like Object Storage or Autonomous Database without going over the public internet. Traffic stays on the Oracle backbone, meaning better performance and tighter security. No internet gateway or NAT gateway is required to reach those specific services.

NAT Gateway – Internet Access
A NAT Gateway allows outbound internet access for private subnets, while keeping those instances hidden from unsolicited inbound traffic. When a host in the private network initiates an internet-bound connection, the NAT device’s public IP address becomes the source IP address for the outbound traffic. The response traffic from the internet therefore uses that public IP address as the destination IP address. The NAT device then routes the response to the host in the private network that initiated the connection.

Private Endpoints – Lock Down Your Services
With Private Endpoints, you can expose services like OKE, Functions, or Object Storage only within a VCN or peered network. It’s the cloud-native way to implement zero-trust within your OCI environment, making sure services aren’t reachable over the public internet unless you explicitly want them to be. You can think of the private endpoint as just another VNIC in your VCN. You can control access to it like you would for any other VNIC: by using security rules

The private endpoint gives hosts within your VCN and your on-premises network access to a single resource within the Oracle service of interest (for example, one database in Autonomous Database Serverless). Compare that private access model with a service gateway (explained before):
If you created five Autonomous Databases for a given VCN, all five would be accessible through a single service gateway by sending requests to a public endpoint for the service. However, with the private endpoint model, there would be five separate private endpoints: one for each Autonomous Database, and each with its own private IP address.
The list of supported services with a service gateway can be found here.
Oracle Services Network (OSN) – The Private Path to Oracle
The Oracle Services Network is the internal highway for communication between your VCN and Oracle-managed services. It underpins things like the Service Gateway and ensures your service traffic doesn’t touch the public internet. When someone says “use OCI’s backbone,” this is what they’re talking about.
Network Load Balancer – Lightweight, Fast, Private
Network Load Balancer is a load balancing service which operates at Layer-3 and Layer-4 of the Open Systems Interconnection (OSI) model. This service provides the benefits of high availability and offers high throughput while maintaining ultra low latency. You have three modes in Network Load Balancer in which you can operate:
- Full Network Address Translation (NAT) mode
- Source Preservation mode
- Transparent (Source/Destination Preservation) mode
The Network Load Balancer service supports three primary network load balancer policy types:
- 5-Tuple Hash: Routes incoming traffic based on 5-Tuple (source IP and port, destination IP and port, protocol) Hash. This is the default network load balancer policy.
- 3-Tuple Hash: Routes incoming traffic based on 3-Tuple (source IP, destination IP, protocol) Hash.
- 2-Tuple Hash: Routes incoming traffic based on 2-Tuple (source IP, destination IP) Hash.
Site-to-Site VPN – The Hybrid Gateway
Connecting your on-premises network to OCI? The Site-to-Site VPN offers a quick, secure way to do it. It uses IPSec tunnels, and while it’s great for development and backup connectivity, you might find bandwidth a bit constrained for production workloads. That’s where FastConnect steps in.
When you set up Site-to-Site VPN, it has two redundant IPSec tunnels. Oracle encourages you to configure your CPE device to use both tunnels (if your device supports it).

FastConnect – Dedicated, Predictable Connectivity
FastConnect gives you a private, dedicated connection between your data center and OCI. It’s the go-to solution when you need stable, high-throughput performance. It comes via Oracle partners, 3rd party providers, or colocations and bypasses the public internet entirely. In hybrid setups, FastConnect is the gold standard.

Have a look at the FastConnect Redundancy Best Practices!
IPsec over FastConnect
You can also layer IPSec encryption over FastConnect, giving you the security of VPN and the performance of FastConnect. This is especially useful for compliance or regulatory scenarios that demand encryption at every hop, even over private circuits.

Note: IPSec over FastConnect is available for all three connectivity models (partner, third-party provider, colocation with Oracle) and multiple IPSec tunnels can exist over a single FastConnect virtual circuit.
FastConnect – MACsec Encryption
FastConnect natively supports line-rate encryption between the FastConnect edge device and your CPE without concern for the cryptographic overhead associated with other methods of encryption, such as IPsec VPNs. With MACsec, customers can secure and protect all their traffic between on-premises and OCI from threats, such as intrusions, eavesdropping, and man-in-the-middle attacks.
Border Gateway Protocol (BGP) – The Routing Protocol of the Internet
If you are using FastConnect, Site-to-Site VPN, or any complex DRG routing scenario, you are likely working with BGP. OCI uses BGP to dynamically exchange routes between your on-premises network and your DRG.
BGP enables route prioritization, failover, and smarter traffic engineering. You’ll need to understand concepts like ASNs, route advertisements, and local preference.
BGP is also essential in multi-DRG and transitive routing topologies, where path selection and traffic symmetry matter.
Transitive Routing
You can have a VCN that acts as a hub, routing traffic between spokes. This is crucial for building scalable, shared services architectures. Using DRG attachments and route rules, you can create full-mesh or hub-and-spoke topologies with total control. Transit Routing can also be used to transit from one OCI region to another OCI region leveraging the OCI backbone.
The three primary transit routing scenarios are:
- Access between several networks through a single DRG with a firewall between networks
- Access to several VCNs in the same region
- Private access to Oracle services

Inter-Tenancy Connectivity – Across Tenants
In multi-tenant scenarios, for example between business units or regions, inter-tenancy connectivity allows you to securely link VCNs across OCI accounts. This might involve shared DRGs or peering setups. It’s increasingly relevant for large enterprises where cloud governance splits resources across different tenancies but still needs seamless interconnectivity.
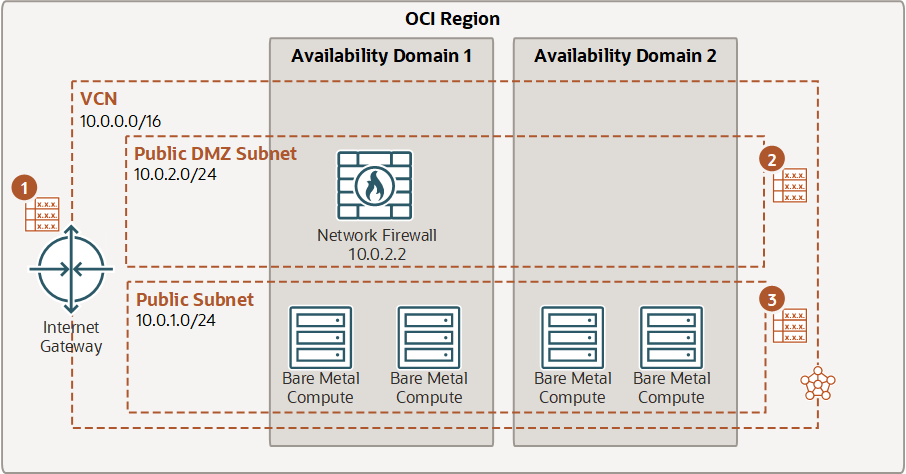
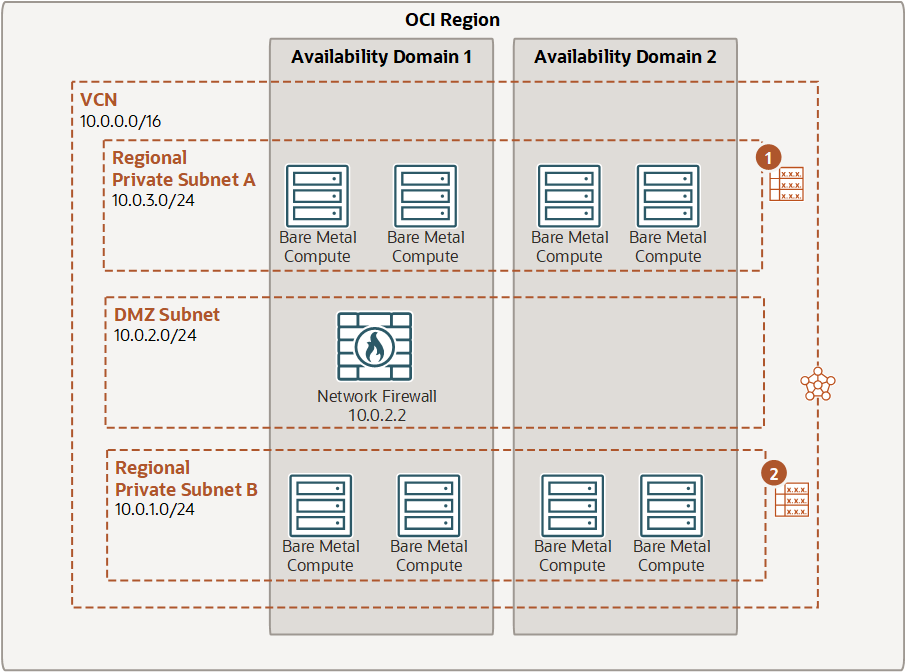
Network Firewall – Powered by Palo Alto Networks
The OCI Network Firewall is a managed, cloud-native network security service. It acts as a stateful, Layer 3 to 7 firewall that inspects and filters network traffic at a granular, application-aware level. You can think of it as a fully integrated, Oracle-managed instance of Palo Alto’s firewall technology with all the power of Palo Alto, but integrated into OCI’s networking fabric.
In this example, routing is configured from an on-premises network through a dynamic routing gateway (DRG) to the firewall. Traffic is routed from the DRG, through the firewall, and then from the firewall subnet to a private subnet
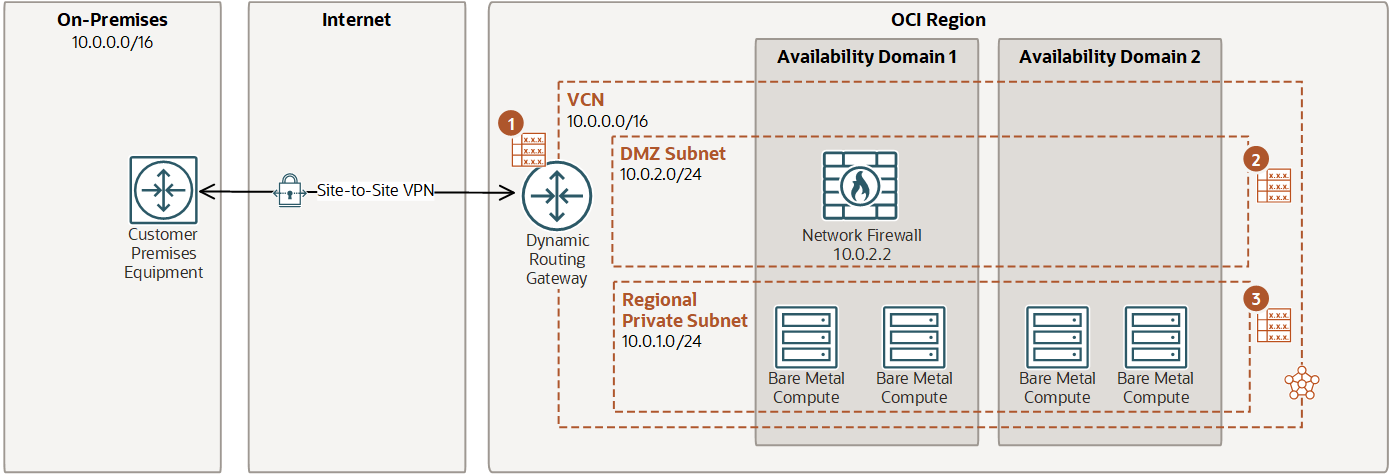
In this example, routing is configured from the internet to the firewall. Traffic is routed from the internet gateway (IGW), through the firewall, and then from the firewall subnet to a public subnet.
In this example, routing is configured from a subnet to the firewall. Traffic is routed from Subnet A, through the firewall, and then from the firewall subnet to Subnet B.
Zero Trust Packet Routing (ZPR)
Oracle Cloud Infrastructure Zero Trust Packet Routing (ZPR) protects sensitive data from unauthorized access through intent-based security policies that you write for the OCI resources that you assign security attributes to. Security attributes are labels that ZPR uses to identify and organize OCI resources. ZPR enforces policy at the network level each time access is requested, regardless of potential network architecture changes or misconfigurations.
ZPR is built on top of existing network security group (NSG) and security control list (SCL) rules. For a packet to reach a target, it must pass all NSG and SCL rules, and ZPR policy. If any NSG, SCL, or ZPR rule or policy doesn’t allow traffic, the request is dropped.
Wrapping Up
OCI’s networking stack is deep, flexible, and modern. Whether you are an enterprise architect, a security specialist, or a hands-on cloud engineer, mastering these building blocks is key. Not just to pass the OCI 2025 Network Professional certification, but to design secure, scalable, and resilient cloud networks. 🙂