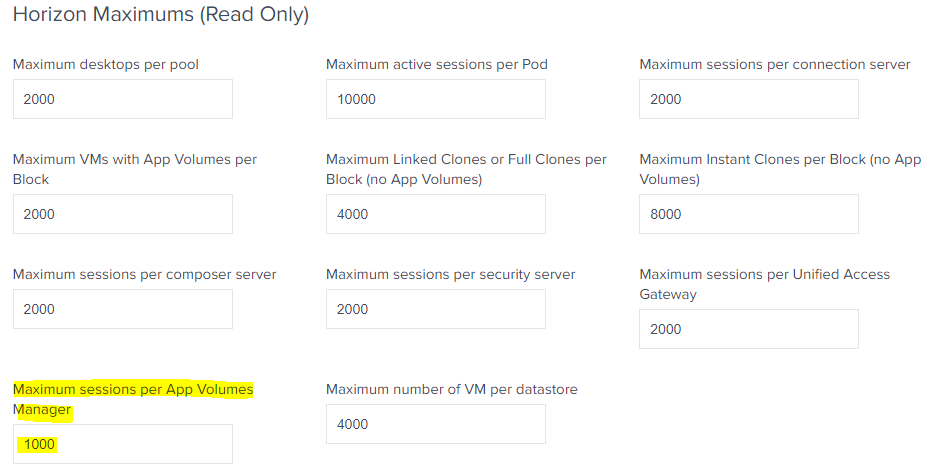
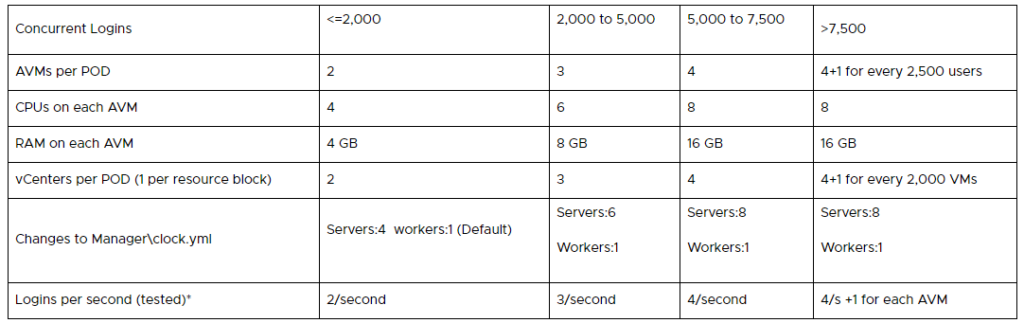
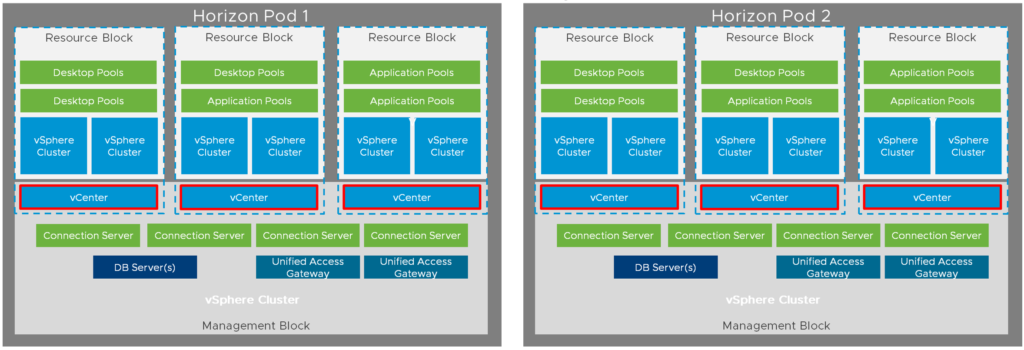
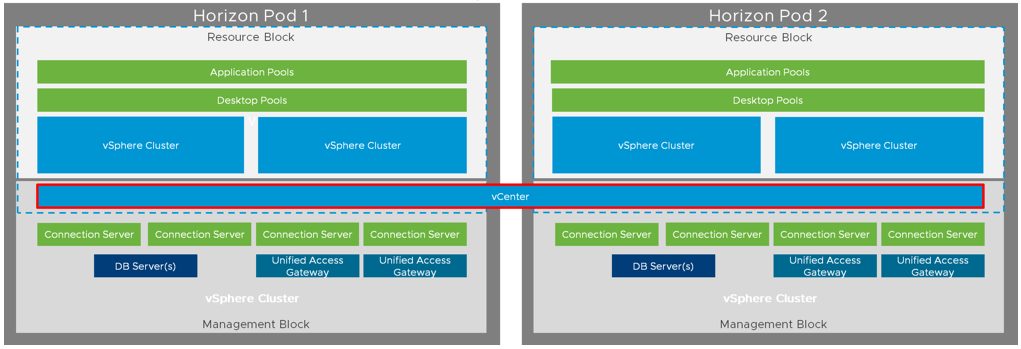
VMware’s Tanzu Kubernetes Grid
Since the announcement of Tanzu and Project Pacific at VMworld US 2019 a lot happened and people want to know more what VMware is doing with Kubernetes. This article is a summary about the past announcements in the cloud native space. As you already may know at this point, when we talk about Kubernetes, VMware made very important acquisitions regarding this open-source project.

It all started with the acquisition of Heptio, a leader in the open Kubernetes ecosystem. With two of the creators of Kubernetes (K8s), namely Joe Beda and Craig McLuckie, Heptio should help to drive the cloud native technologies within VMware forward and help customers and the open source community to accelerate the enterprise adoption of K8s on-premises and in multi-cloud environments.
The second important milestone was in May 2019, where the intent to acquire Bitnami, a leader in application packaging solutions for Kubernetes environments, has been made public. At VMworld US 2019 VMware announced Project Galleon to bring Bitnami capabilities to the enterprise to offer customized application stacks to their developers.
One week before VMworld US 2019 the third milestone has been communicated, the agreement to acquire Pivotal. The solutions from Pivotal have helped customers learn how to adopt modern techniques to build and run software and they are the provider of the most popular developer framework for Java, Spring and Spring Boot.
On the 26th August 2019, VMware gave those strategic acquisitions the name VMware Tanzu. Tanzu should help customers to BUILD modern applications, RUN Kubernetes consistently in any cloud and MANAGE all Kubernetes environments from a single point of control (single console).

Tanzu Mission Control (TMC) is the cornerstone of the Tanzu portfolio and should help to relieve the problems we have or going to have with a lof of Kubernetes clusters (fragmentation) within organizations. Multiple teams in the same company are creating and deploying applications on their own K8s clusters – on-premises or in any cloud (e.g. AWS, Azure or GCP). There are many valid reasons why different teams choose different clouds for different applications, but is causing fragmentation and management overhead because you are faced with different management consoles and silo’d infrastructures. And what about visibility into app/cluster health, cost, security requirements, IAM, networking policies and so on? Tanzu MC let customers manage all their K8s clusters across vSphere, VMware PKS, public cloud, managed services or even DIY – from a single console.

It lets you provision K8s clusters in any environment and configure policies which establish guardrails. Those guardrails are configured by IT operations and they will apply policies for access, security, backup or quotas.
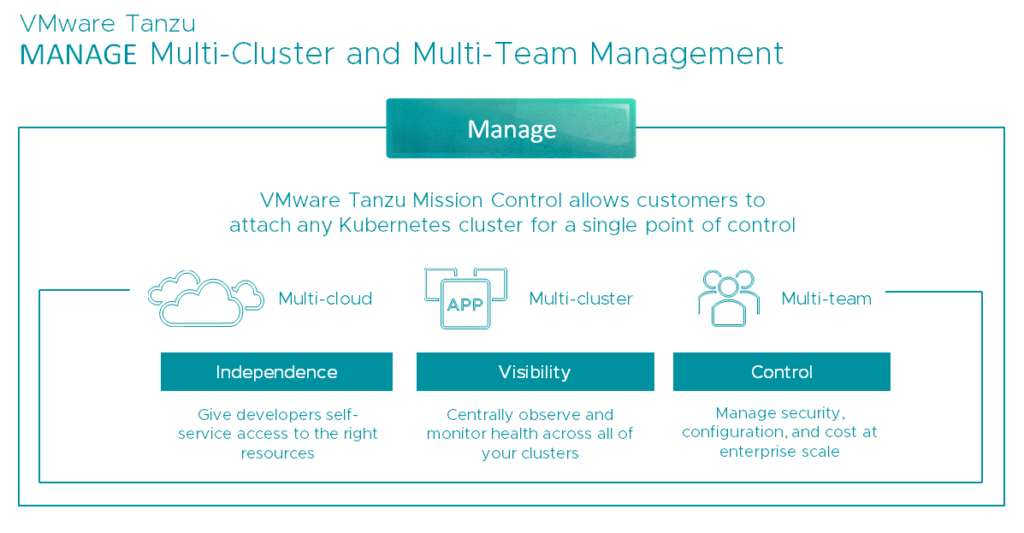
As you can see, Mission Control has a lot of capabilities. If you look at the last two images you can see that you not only can create clusters directly from Tanzu MC, but also have the ability to attach existing K8s clusters. This can be done by installing an agent in the remote K8s cluster, which then provides a secure connection back to Tanzu MC.
We focused on the BUILD and MANAGE layers now. Let’s take a look at the RUN layer which should help us to run Kubernetes consistently across clouds. Without consistency across cloud environments (this includes on-prem) enterprises will struggle to manage their hundred or even thousands of modern apps. It’s just getting too complex.
VMware’s goal in general is to abstract complexity and to make your life easier and for this case VMware has announced the so-called Tanzu Kubernetes Grid (TKG) to provide us a common Kubernetes distribution across all the different environments.
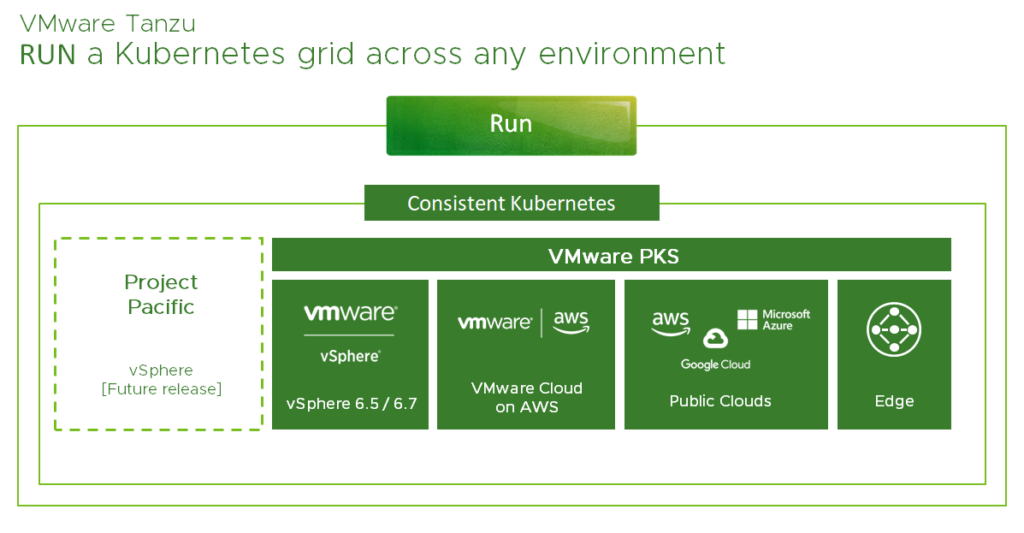
In my understanding TKG means VMware’s Kubernetes distribution, will include Project Pacific as soon as it’s GA and is based on three principles:
- Open Source Kubernetes – tested and secured
- Cluster Lifecycle management – fully integrated
- 24×7 support
Meaning, that TKG is based on open source technologies, packaged for enterprises and supported by VMware’s Global Support Services (GSS). Based on these facts you could say, that today your Kubernetes journey with VMware starts with VMware PKS. PKS is the way VMware deliver the principles of Tanzu today – across vSphere, VCF, VMC on AWS, public clouds and edge.
Project Pacific
Project Pacific, which has been announced at VMworld US 2019 as well, is a complement to VMware PKS and will be available in a future release. If you are not familiar with Pacific yet, then read the introduction of Project Pacific. Otherwise, it’s sufficient to say, that Project Pacific means the re-architecture of vSphere to natively integrate Kubernetes. There is no nesting or any kind of it and it’s not Kubernetes in vSphere. It’s more like vSphere on top of Kubernetes since the idea of this project is to use Kubernetes to steer vSphere.

Pacific will embed Kubernetes into the control plane of vSphere and converge VMs and containers on the same underlying platform. This will give the IT operators the possibility to see and manage Kubernetes from the vSphere client and provide developers the interfaces and tools they are already familiar with.
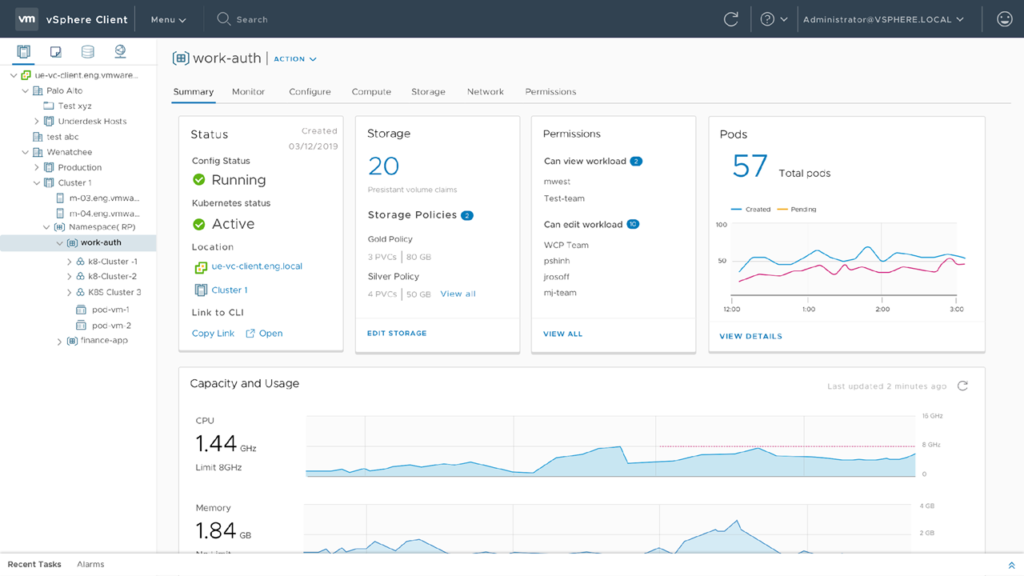
If you are interested in the Project Pacific Beta Program, you’ll find all information here.
I would have access to download the vSphere build which includes Project Pacific, but I haven’t got time at the moment and my home lab is also not ready yet. We hear customers asking about the requirements for Pacific. If you watch all the different recordings from the VMworld sessions about Project Pacific and the Supervisor Cluster, then we could predict, that only NSX-T is a prerequisite to deploy and enable Project Pacific. This slide shows why NSX-T is part of Pacific:
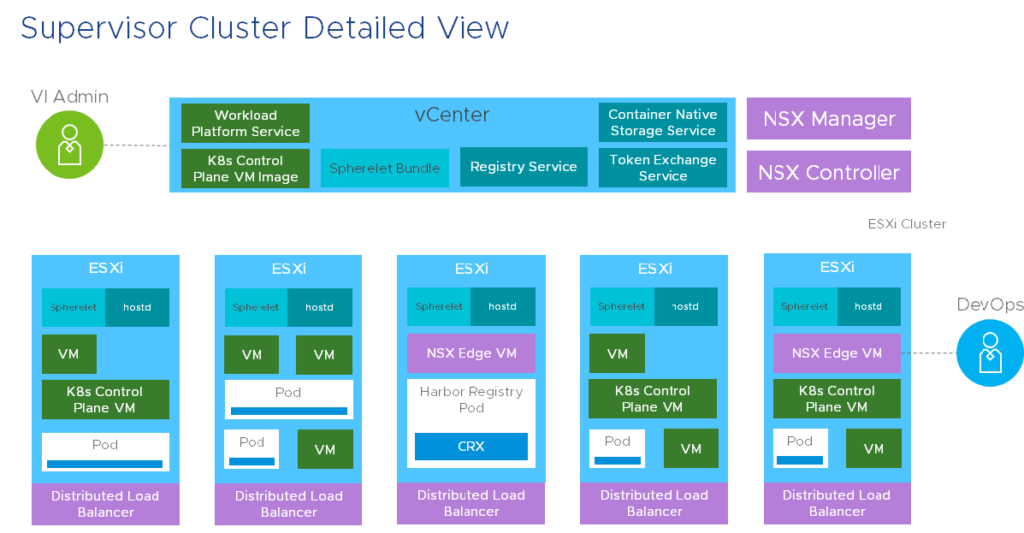 From this slide (from session HBI1452BE) we learn that a load balancer built on NSX Edge is sitting in front of the three K8s Control Plane VMs and that you’ll find a Distributed Load Balancer spanned across all hosts to enable the pod-to-pod or east-west communication.
From this slide (from session HBI1452BE) we learn that a load balancer built on NSX Edge is sitting in front of the three K8s Control Plane VMs and that you’ll find a Distributed Load Balancer spanned across all hosts to enable the pod-to-pod or east-west communication.
Nobody of the speakers ever mentioned vSAN as a requirement and I also doubt that vSAN is going to be a prerequisite for Pacific.
You may ask yourself now which Kubernetes version will be shipped with ESXi and how you upgrade your K8s distribution? And what about if this setup with Pacific is too “static” for you? Well, for the Supervisor Clusters VMware releases patches with vSphere and you apply them with the known tools like VUM. For your own built K8s clusters, or if you need to deploy Guest Clusters, then the upgrades are easy as well. You just have to download the new distribution and specify the new version/distribution in the (Guest Cluster Manager) YAML file.
Conclusion
Rumors say that Pacific will be shipped with the upcoming vSphere 7.0 release, which even should include NSX-T 3.0. For now we don’t know when Pacific will be shipped with vSphere and if it really will be included with the next major version. I would be impressed if that would be the case, because you need a stable hypervisor version, then a new NSX-T version is also coming into play and in the end Pacific relies on these stable components. Our experience has shown that the first release normally is never perfect and stable and that we need to wait for the next cycle or quarter. With that in mind I would say that Pacific could be GA in Q3 2020 or Q4 2020. And beside that the beta program for Project Pacific just has started!
Nevertheless I think that Pacific and the whole Kubernetes Grid from VMware will help customers to run their (modern) apps on any Kubernetes infrastructure. We just need to be aware that there are some limitations when K8s is embedded in the hypervisor, but for these use cases Guest Clusters could be deployed anyway.
In my opinion Tanzu and Pacific alone don’t make “the” big difference. It’s getting more interesting if you talk about multi-cloud management with vRA 8.0 (or vRA Cloud), use Tanzu MC for the management of all your K8s clusters, networking with NSX-T (and NSX Cloud), create a container host with a container image (via vRA’s Service Broker) for AI- and ML-based workloads and provide the GPU over the network with Bitfusion.

Looking forward to such conversations! 😀